Watson検索システムの作り方・応用編
~DiscoveryとKnowledge Studioの連携方法~
Watsonは、IBMクラウドに登録するだけで誰でも使うことができるAI(人工知能)です(無料プランあり)。
今回は、Discoveryを使って、検索システムを作成していきます。
目次
Knowledge Studioとは
IBM Watsonシリーズの特有の表現を覚えさせることができるサービスです。
また、同シリーズのクラウド型情報検索エンジンDiscovery と連携することができます。
Discovery については、Discoveryについて解説した記事で詳しく紹介しております。
DiscoveryとKnowledge Studioが連携することで何ができるようになるのか
Knowledge Studioと連携することによって、業界特有の用語を扱った文章を検索システムに取り込む場合でも検索精度を高めることができます。
「特有の表現を覚えさせることができるサービス」であるKnowledge Studioと連携することでエンティティー抽出と関係抽出ができるようになり、具体的にはこんなことができるようにもなります。
*医療画像装置に関する膨大な量の特許文書をアノテーションしていき、検索システムから調べたい内容を自然文で検索して、情報の記載された文書データを引き出す。(IBMより引用)
Knowledge Studioを使うまでの設定
それでは、DiscoveryとKnowledge Studioの連携をするには、どうしたら良いでしょうか?
まずはKnowledge Studioの設定から説明をします。
※これ以降、Knowledge Studioについて、WKS(Watson Knowledge Studio)と省略させていただきます。
まずは、IBM Watsonシリーズのサービスを使っていくために、フリーアカウントを作成してください。
こちらから作成をお願いします。
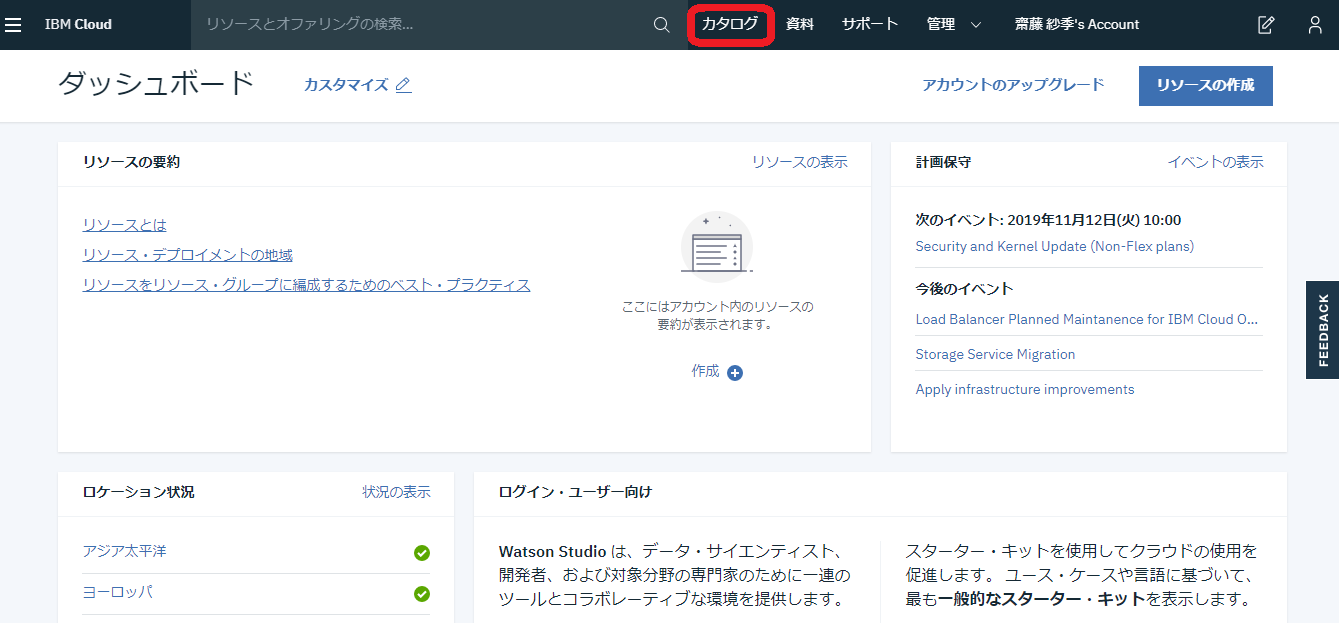
アカウント作成後、ログインを行い、上の画面が出てきたら、「カタログ」をクリックします。
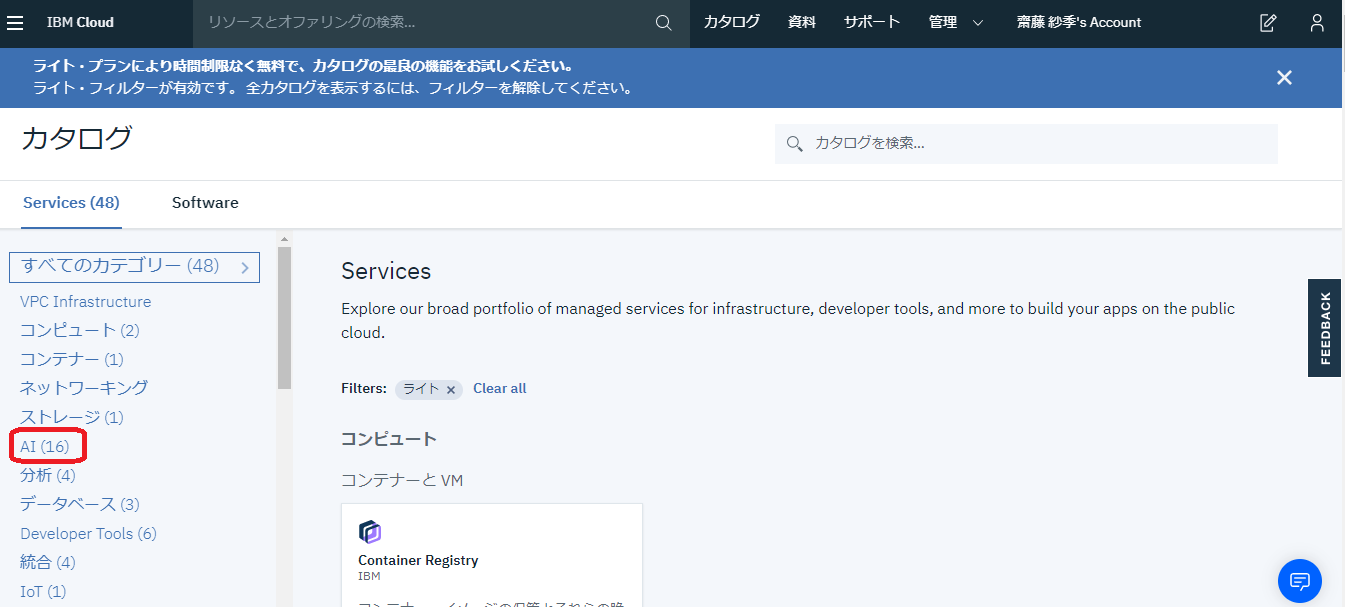
上のような画面が出ますので、左側のカテゴリから「AI」をクリックします。
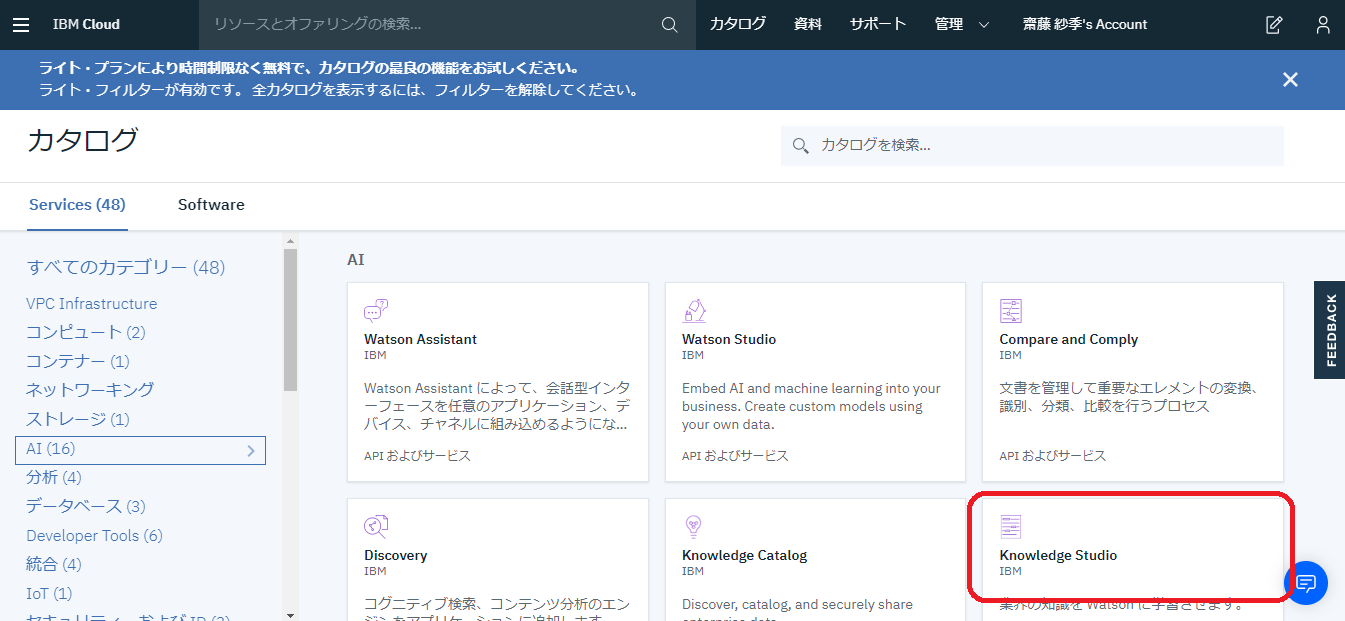
「Knowledge Studio」がありますので、こちらをクリックしてください。
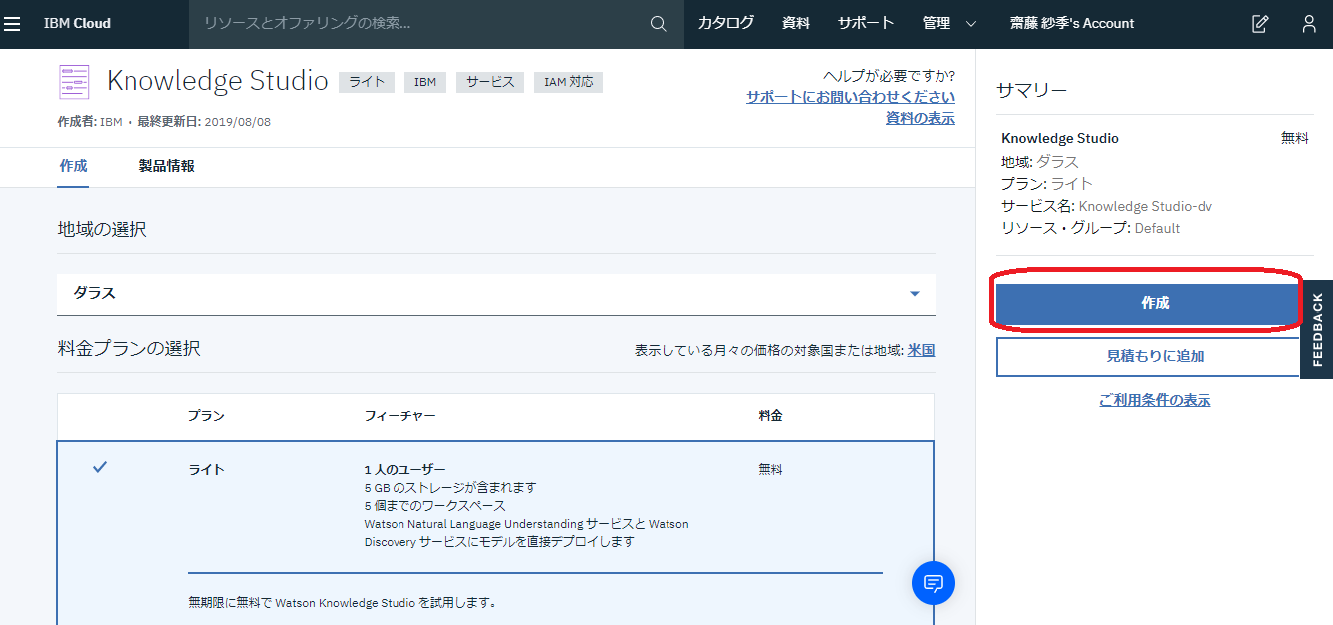
上のような画面が出るかと思いますので、ライトプランを選択し、作成をクリックすれば、無料でKnowledge Studioを使用可能です。
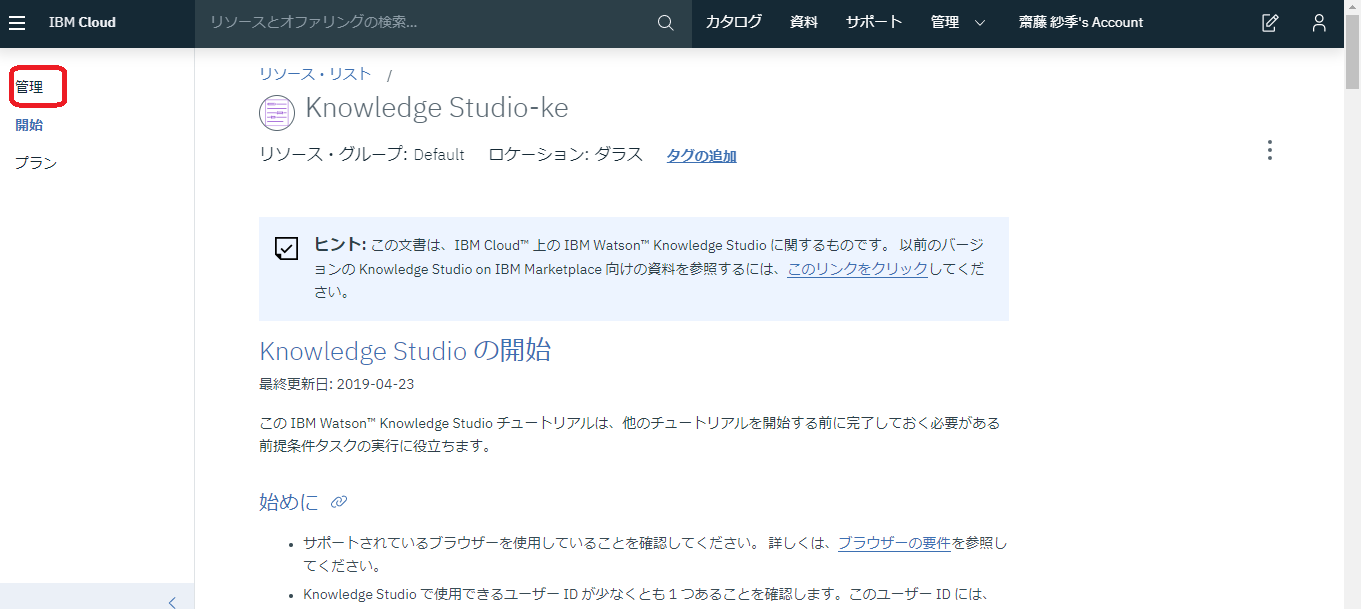
このような画面が表示されるかとおもいます。
「管理」をクリックし、Knowledge Studioを起動できる状態にしましょう。
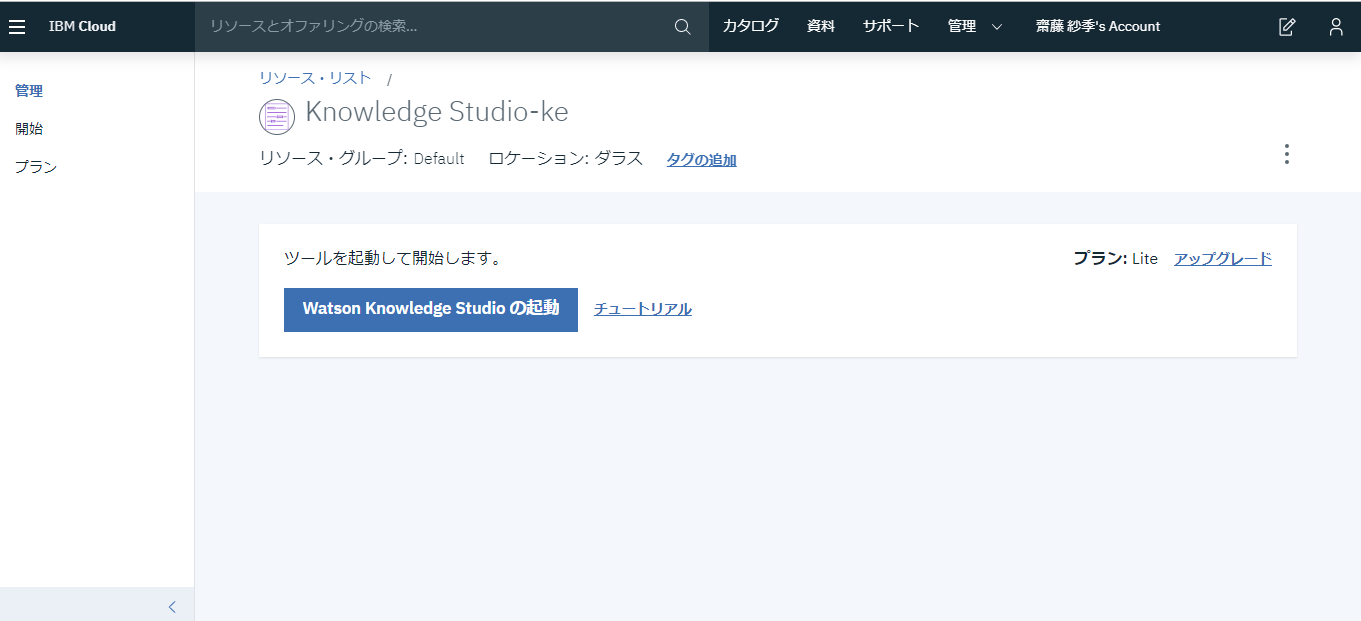
このような画面になったら、起動が可能になります!
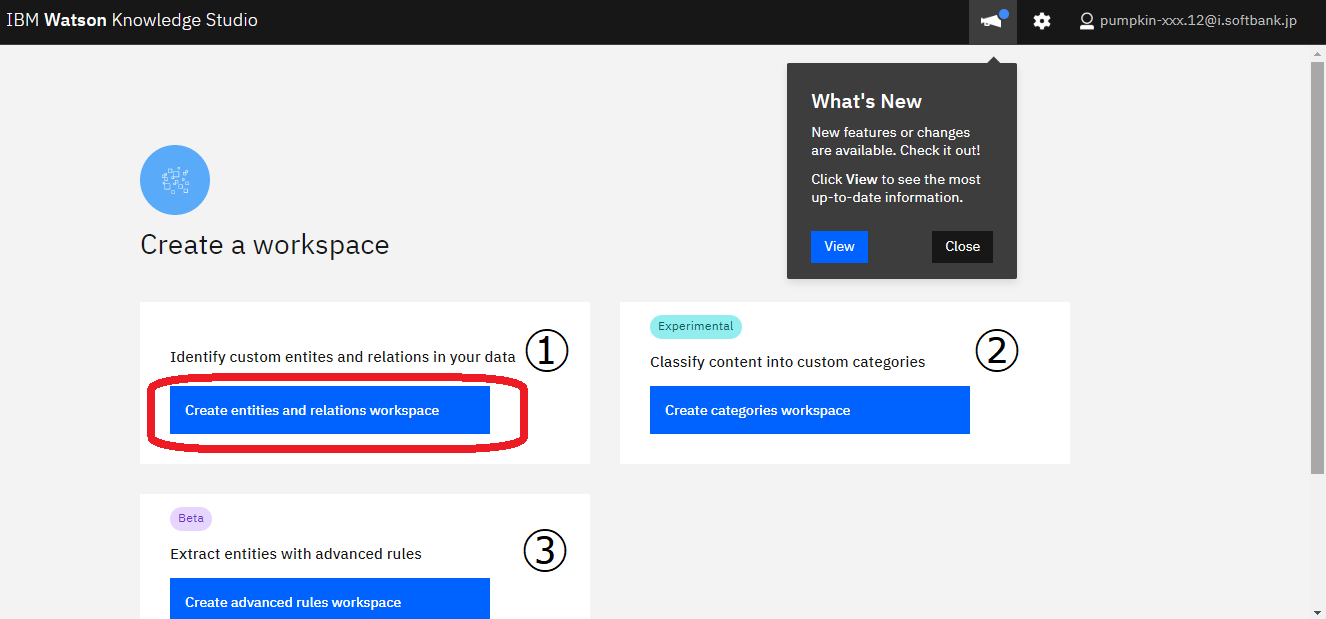
起動したら、このような画面がでてきます。
「What’s New」には、新しくサービスに追加された機能が掲載されておりますので、情報をみたければ「Views」を、特に興味がなければ、「Close」をクリックしてください。
①「データ内のカスタムエンティティーとリレーションを特定する」ワークスペース、②「コンテンツをカスタムカテゴリに分類する」ワークスペース、③「高度なルールでエンティティーを抽出する」ワークスペースに分類できます。
今回は、ベーシックな①「データ内のカスタムエンティティーとリレーションを特定する」ワークスペースを選択しましょう。
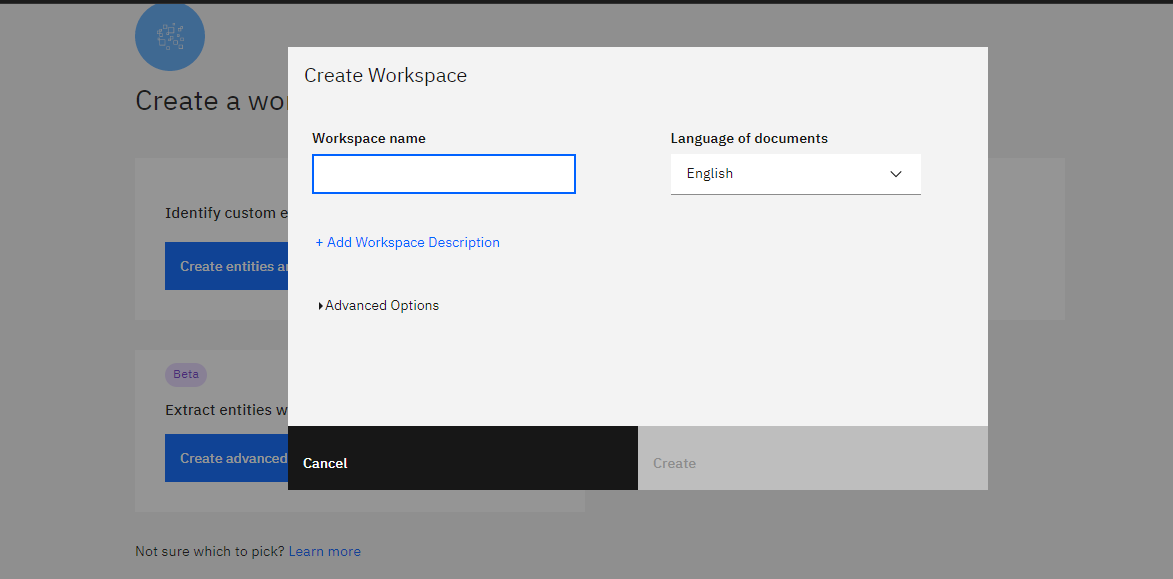
ワークスペースのタイプを選択し終えると、上記のような画面が出てくるかと思います。
「Workspace name」に任意のワークスペース名を記入し、「Language of documents」で「Japanese」を選択し、右下の「Create」をクリックします。
このような画面になったら、設定完了です!
タイプシステムの設計
それでは、タイプシステムの設計に移ります。
タイプシステムの設計とは、エンティティー・タイプ(個々のエンティティーを、データベース上で適切に表現が可能になるよう、抽象化・類型化したもの)を作成していく作業です。
どのようなエンティティーを判別できるようにしたいか設計できます。
※エンティティーについて、詳しく知りたい方は、弊社チャットボット「FirstContact」の記事をご覧ください。
タイプシステムの設計には、JSONデータの読み込みが不可欠です。
※データはJSON形式でないと、アップロードできませんので、ご注意ください。
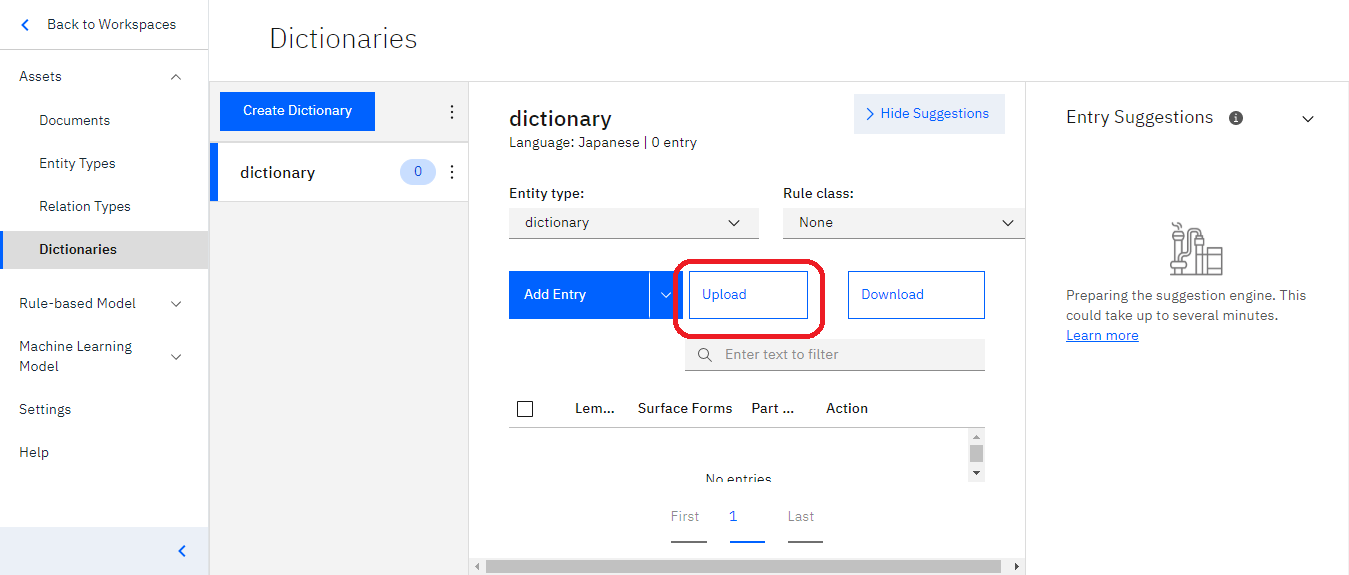
左側の項目から「Entity Types」を選択し、「Upload」をクリックします。
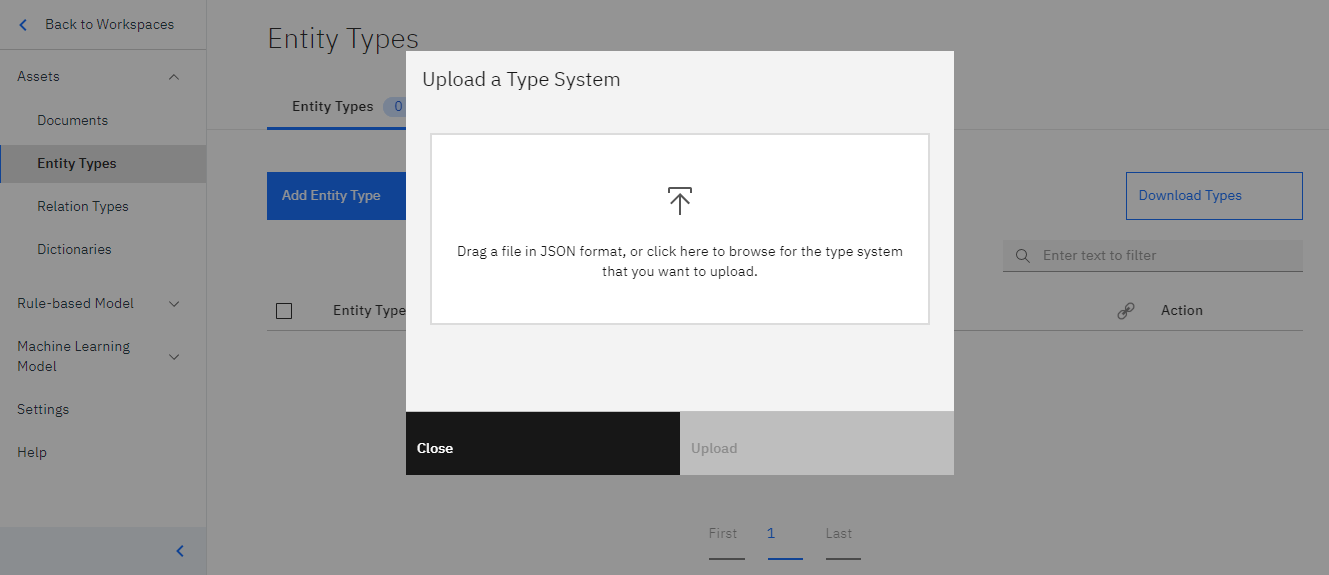
上の画像のようにデータをアップロードする場所がわかりやすく示されますので、こちらにデータをアップロードしてください。
データをドラッグアンドドロップしたら、右下の「Uploading」をクリックしましょう。
データがアップロードされると、緑の丸で囲まれたチェックマークと、アップロードされたデータ名が青色で表示されます。
今回は、IBM CloudのKnowledge Studioのチュートリアルから得た「en-klue2-types.json」というデータを使用しました。
辞書の取り込み
続いて、辞書の取り込みを行います。
辞書の取り込みは、エンティティーに対して品詞を設定していく作業です。
タイプシステムの設計同様、まずは一番左の列「Dictionaries」を選択し、「Uploading」をクリックしてください。
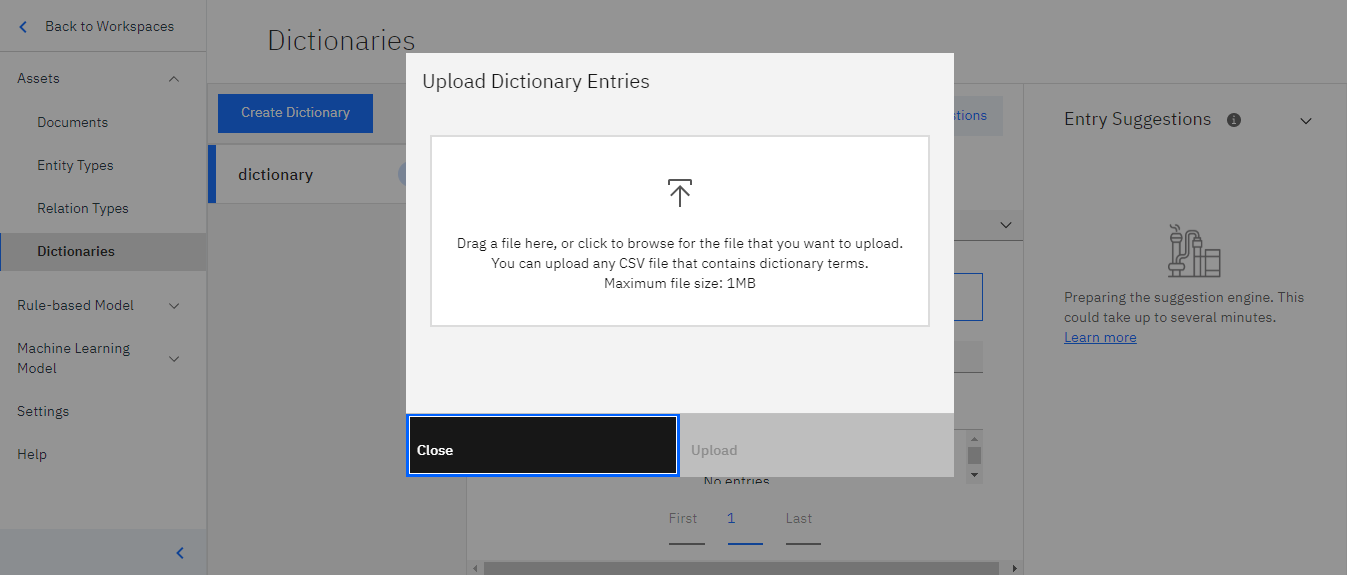
このような画面が開きますので、ここに該当のデータをアップロードしてください。
データをアップロードしたら、右下の「Uploading」が青く光りますので、そちらをクリックしてアップロード完了です。
データがアップロードされると、緑の丸で囲まれたチェックマークと、アップロードされたデータ名が青色で表示されます。
今回は、IBM CloudのKnowledge Studioのチュートリアルから得た「discovery-items-organization.csv」というデータを使用しました。
文書のアップロード
アノテーションをしたい文書をアップロードしていきます。
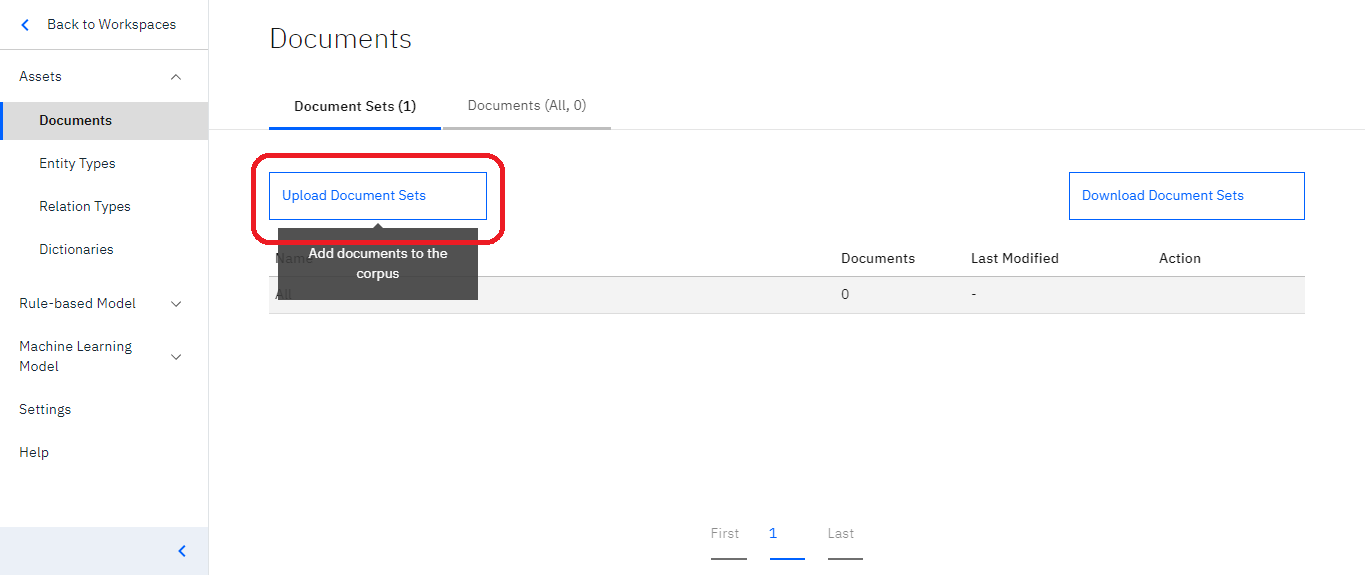
まずは、左列から「Documents」を選択し、Documentsの画面を開きます。
その後、「Upload Document Sets」をクリックします。
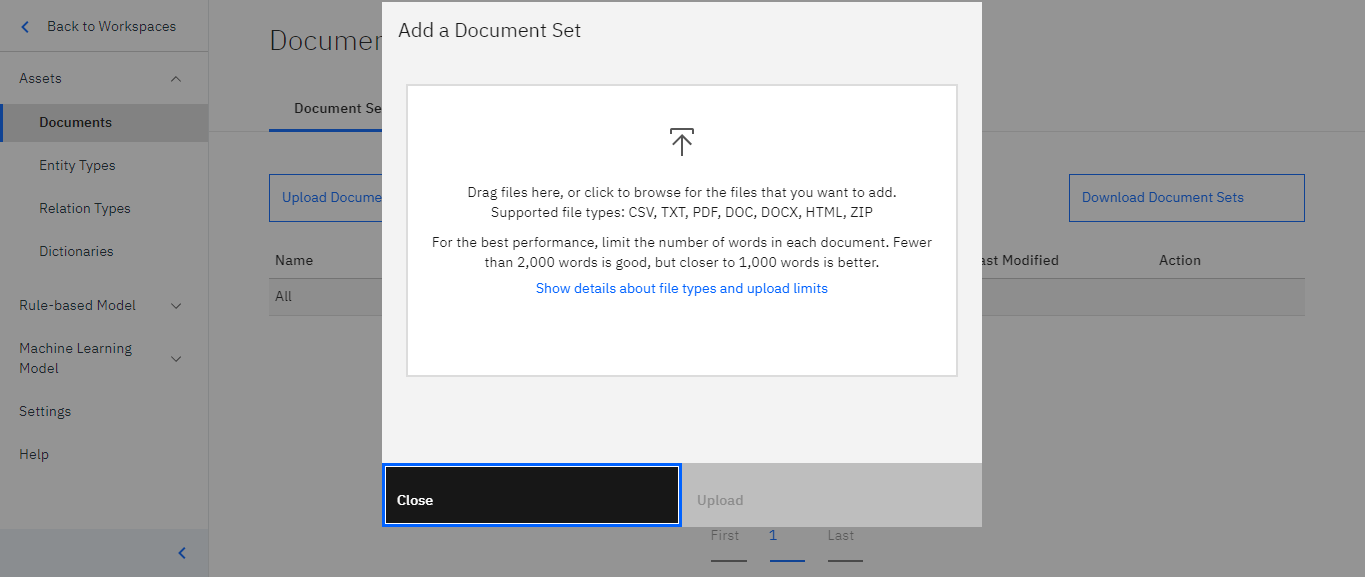
するとこのような画面が開きますので、こちらに該当の文書をアップロードしてください。
データがアップロードされると、緑の丸で囲まれたチェックマークと、アップロードされたデータ名が青色で表示されます。
Discoveryと連携させるには、ある程度の量の文書をここでアップロードし、この後行うアノテーションという作業をしていく必要があります。
アノテーションセットの作成
文書をアップロードしたところで、次にアノテーションという作業に移ります。
アノテーションとは、文書に注釈付けを行う作業のことです。
Knowledge Studioでは3段階のアノテーション方法を実施することができます。
①Mention機能
②Relation機能
③Conference機能
では、こちらの実施方法を順に見ていきましょう。
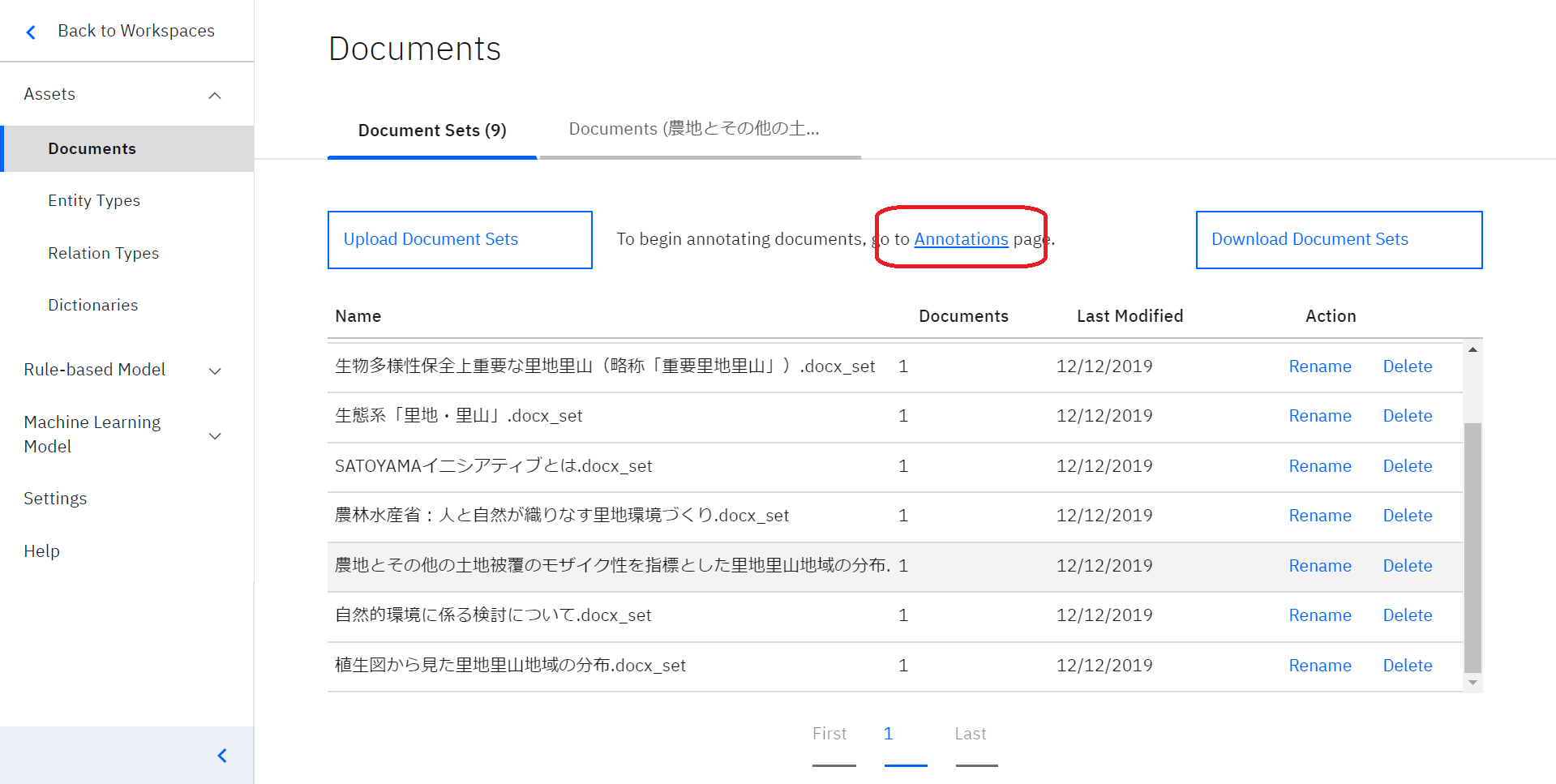
左列の「Documents」を選択し、赤い丸で囲ってある「Annotations」をクリックします。
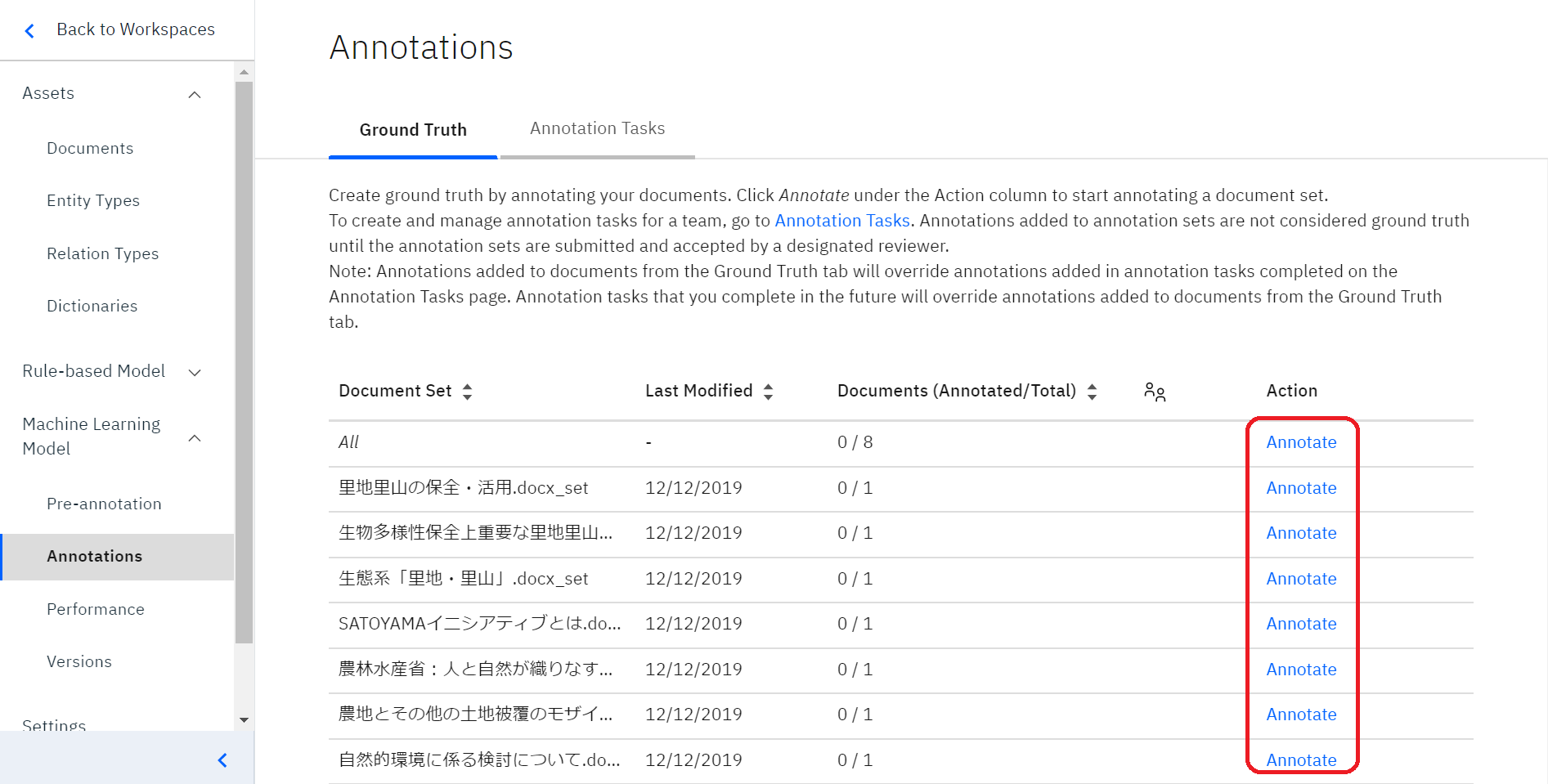
すると、このように「Annotations」というページが開くかと思いますので、アノテーションを行いたいドキュメントを選び、赤い丸で囲ってある「Action」列から、 そのドキュメントの横にある「Annotate」をクリックします。
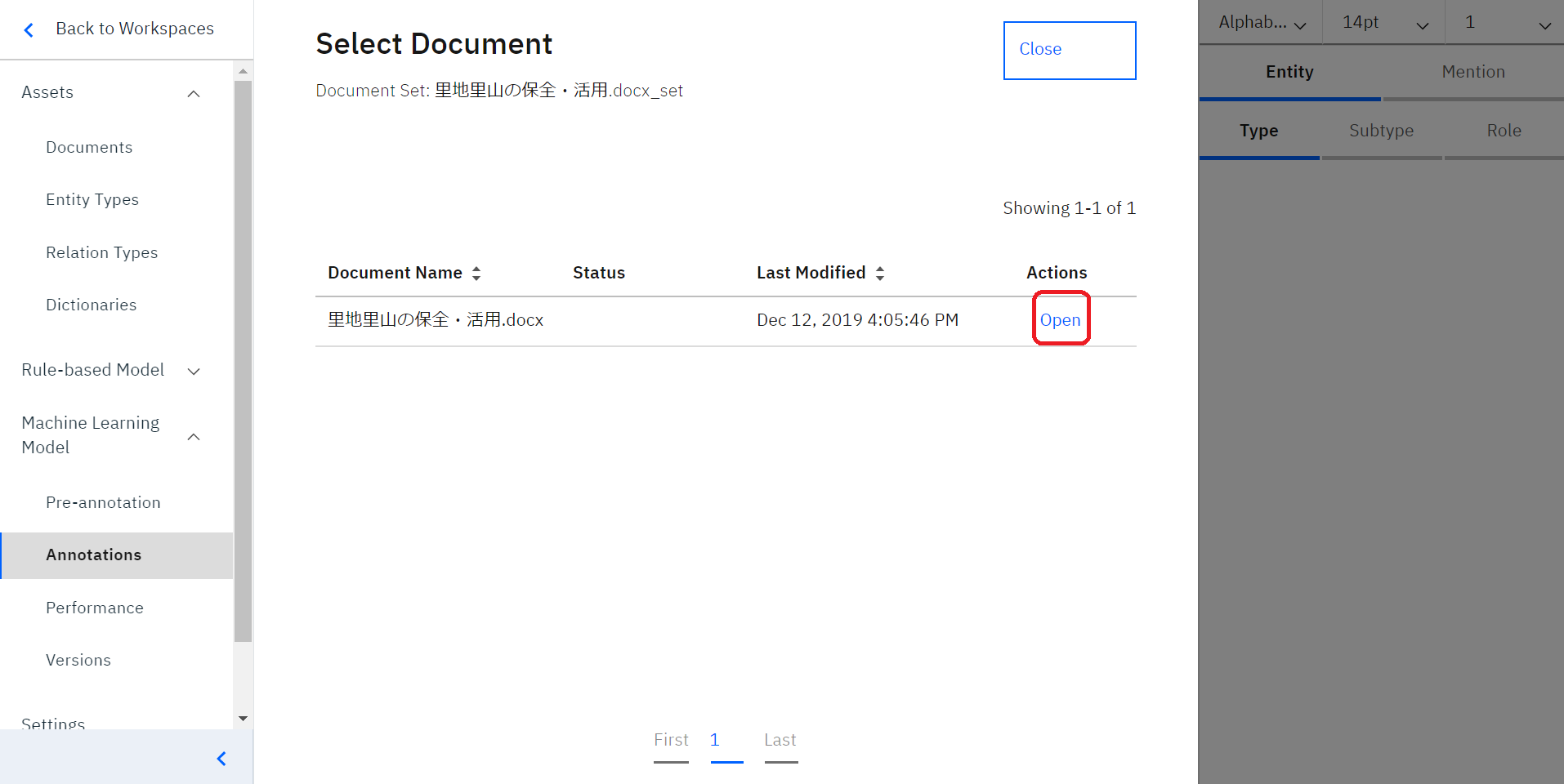
このような画面が開きますので、「Open」をクリックし、いよいよアノテーション開始です!
Mention機能
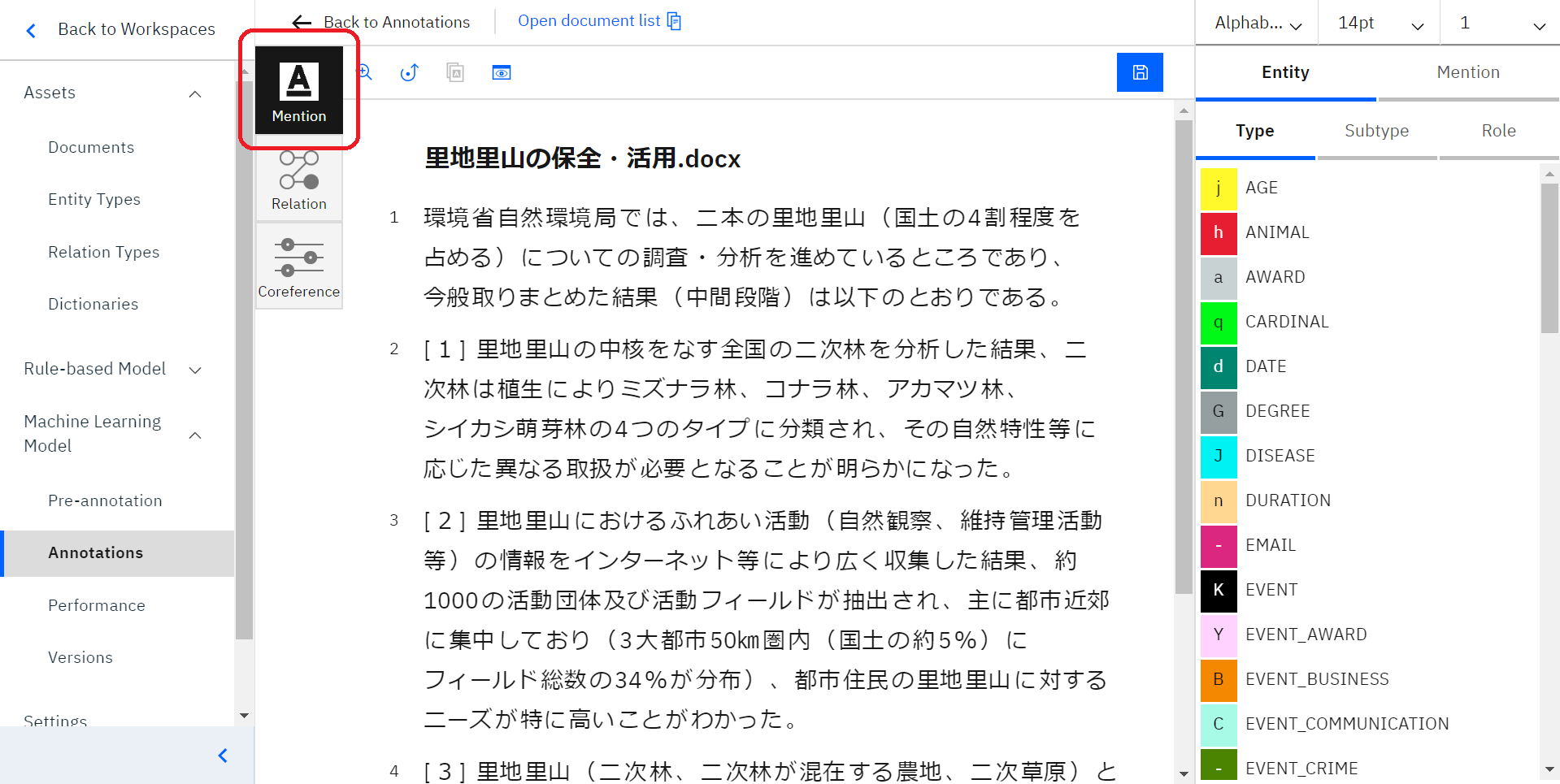
ではまず、①Mention機能から始めていきます。
Mention機能は、ドキュメントにエンティティータイプの設定を行う機能です。
前述した作業が正しく行われていると、上のような画面になっているかと思います。
赤い丸で囲ってある「Mention」を選択すると、Mention機能を使って作業をすることができます。
では作業方法を説明します。
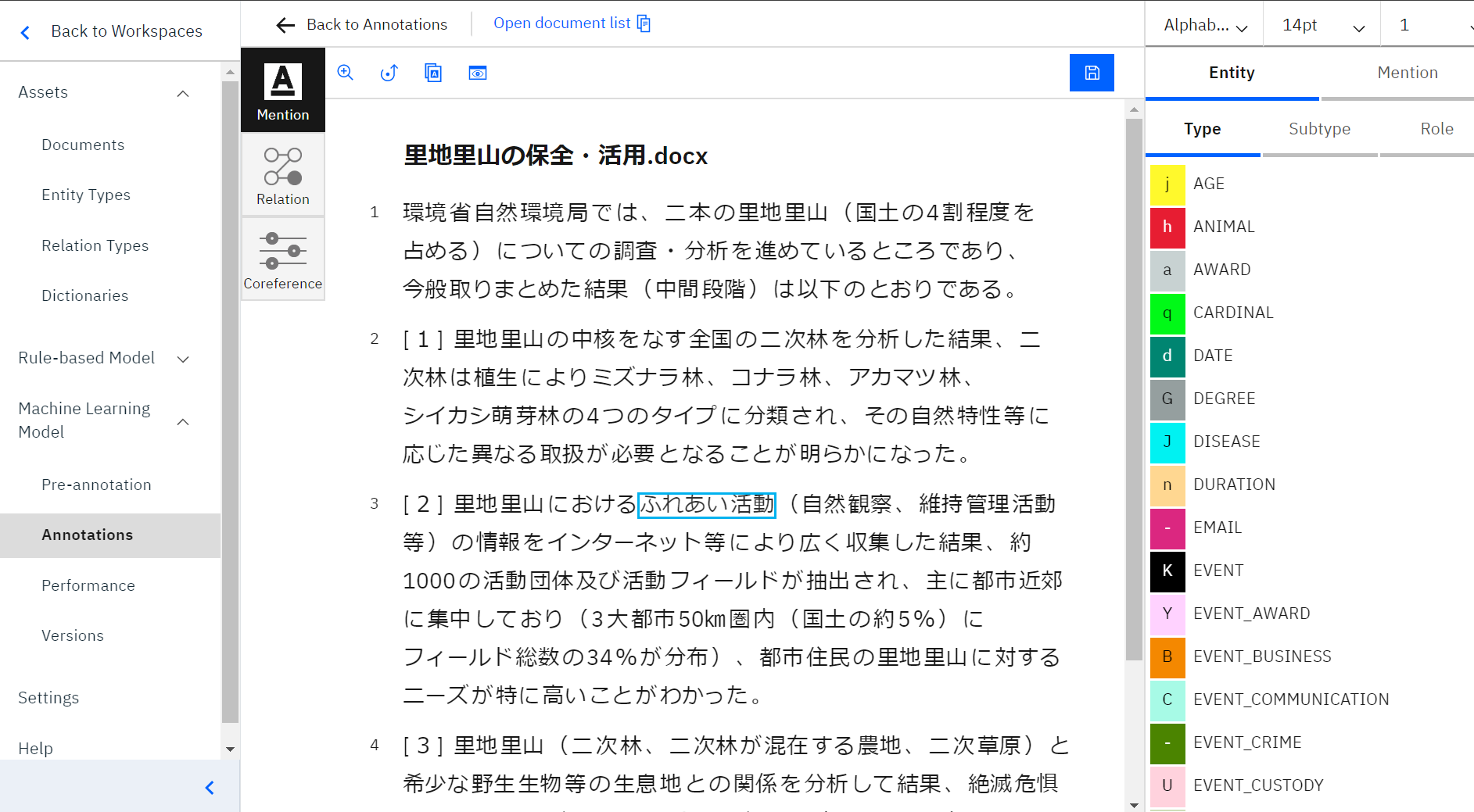
まず、アノテーションしたい言葉の端と端をクリックし、選択すると、上の写真のように青い枠で言葉が囲われます。
この状態で次の作業をします。
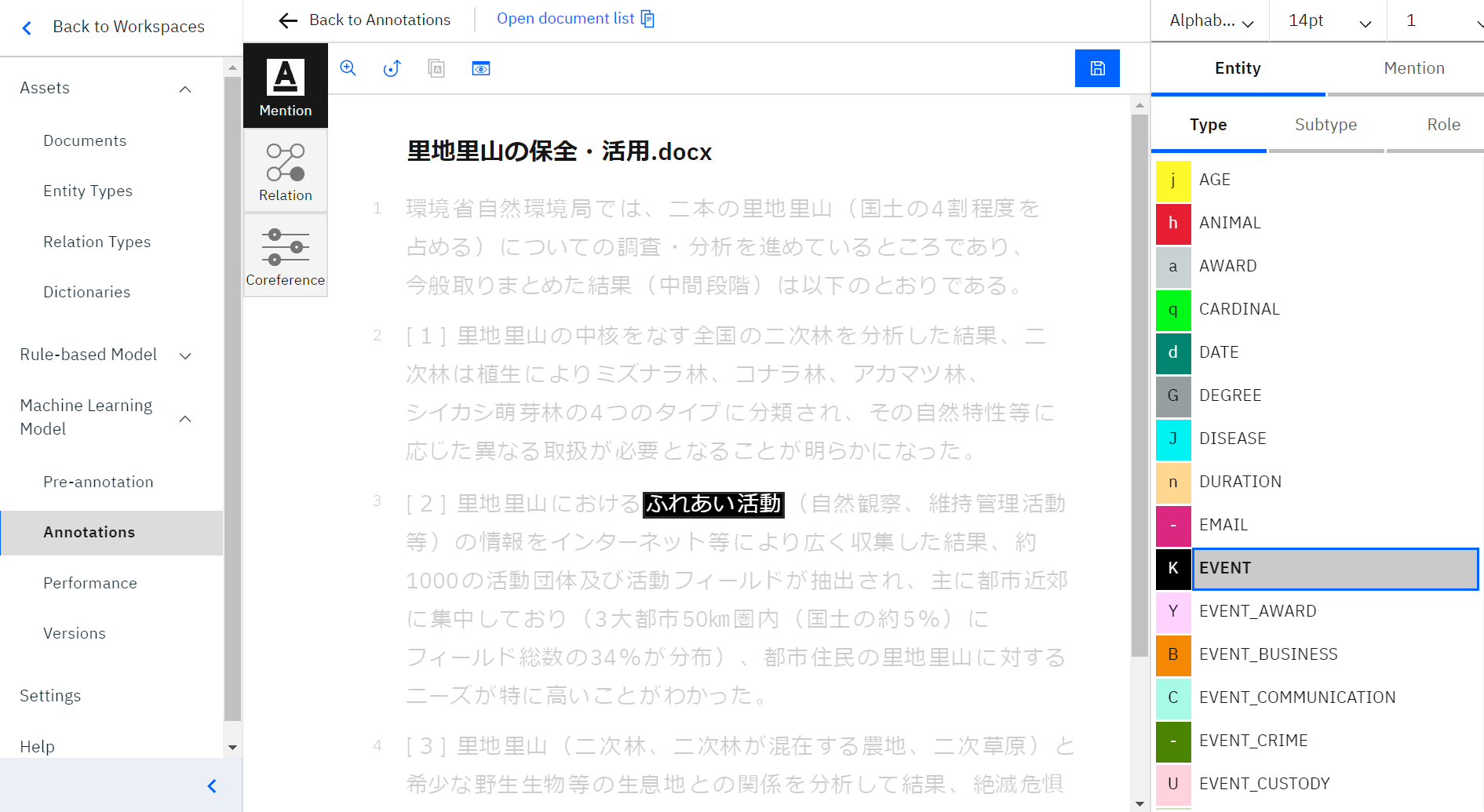
右側から言葉のタイプを選択します。
指定したタイプ名をダブルクリックして、タイプ名が上の画像のようにグレーに染まります。
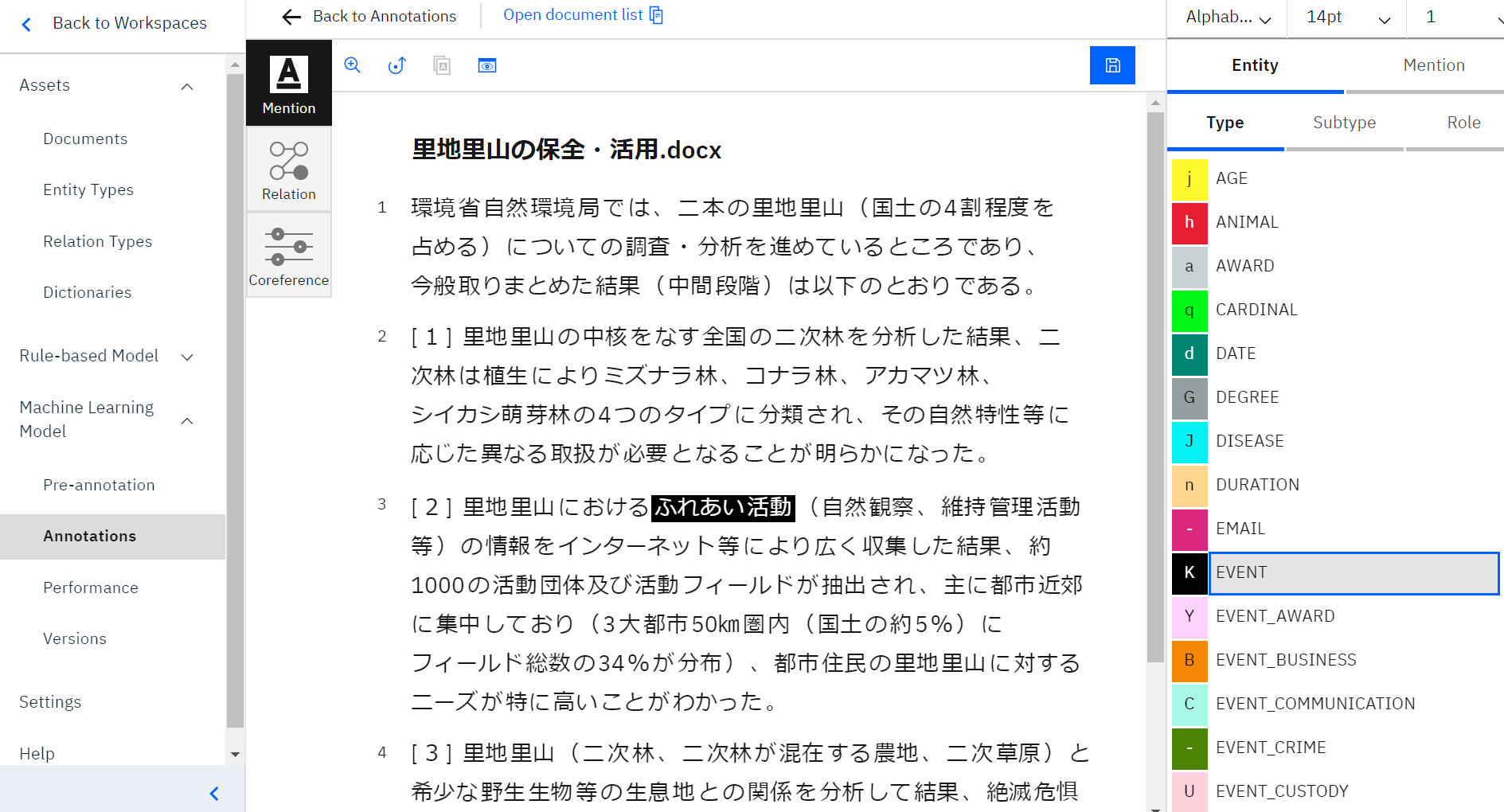
文書のどこかをクリックし、上の画像のように文書の一部が指定したタイプの色にそまっていれば一旦登録完了です。
この作業を繰り返していきます。
上の画像のように品詞を学習させることも可能です。
右側の「Mention」を選択すると、その下のメニューで「NAM(固有名詞)」、「NOM(名詞)」、「PRO(代名詞)」、「NONE(その他)」を選択し、アノテーションしていくことができます。
Relation機能
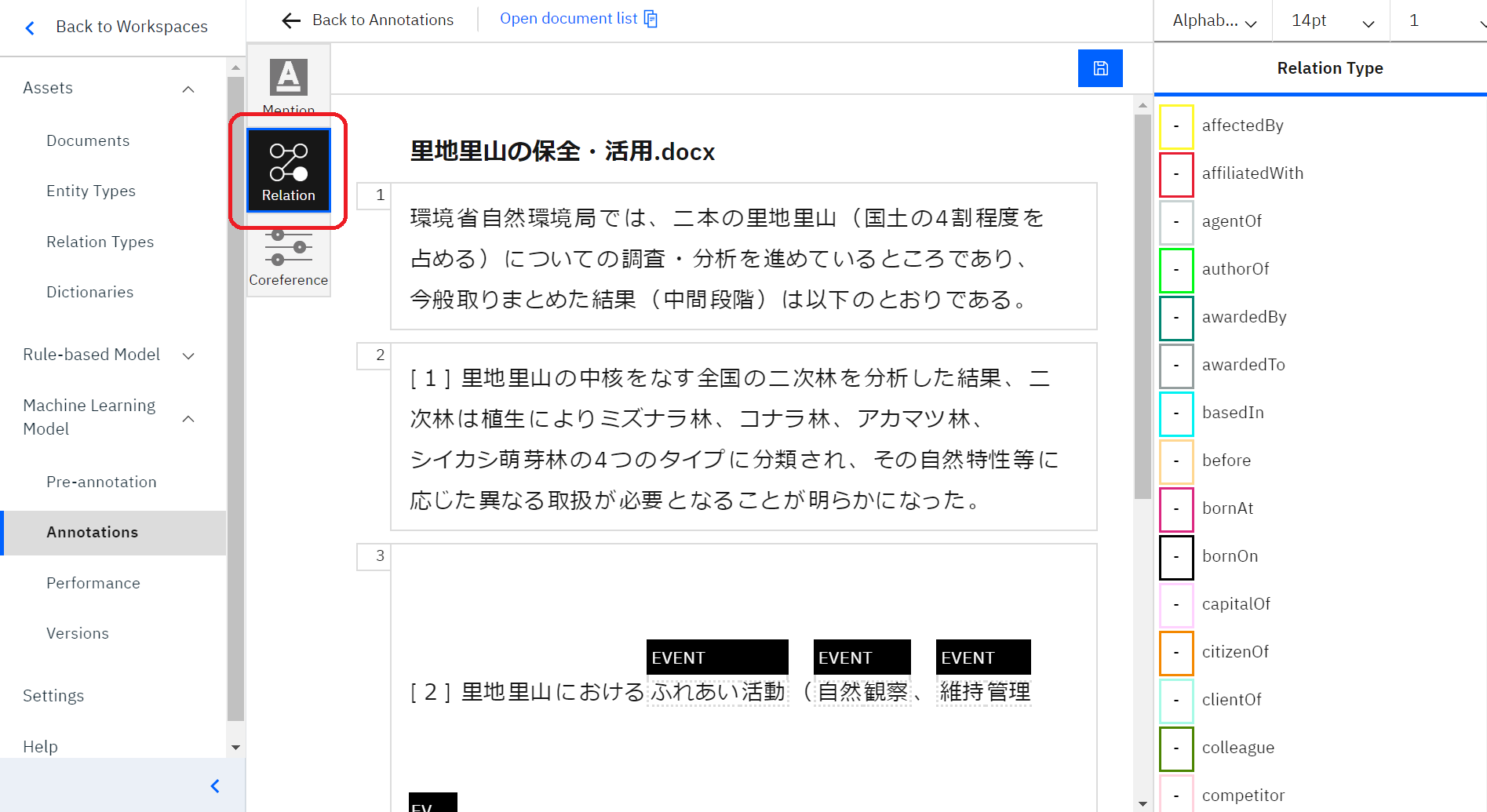
続いて②Relation機能です。Relation機能は、エンティティーとエンティティーの関係性を設定する機能です。
Mentionを選択します。
赤い丸の部分をクリックし、Relation機能をさわれる画面を開きましょう。
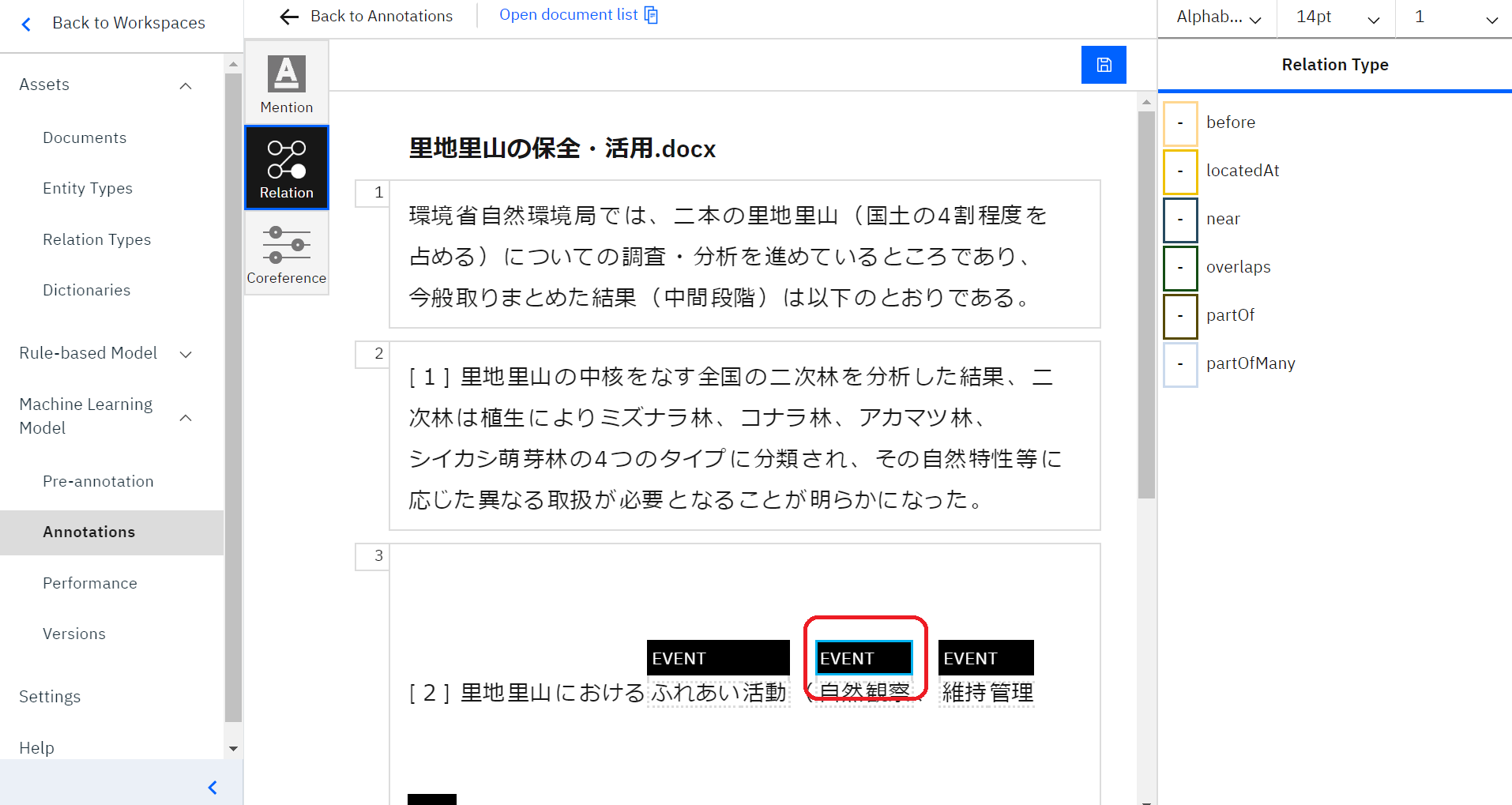
今回私は、「自然観察」と「ふれあい活動」という言葉の関係性を設定します。
まずは、関係性を設定したい1つ目の言葉「自然観察」をダブルクリックして設定します。
言葉をダブルクリックすると、言葉の周りが青くなっているのが分かります。
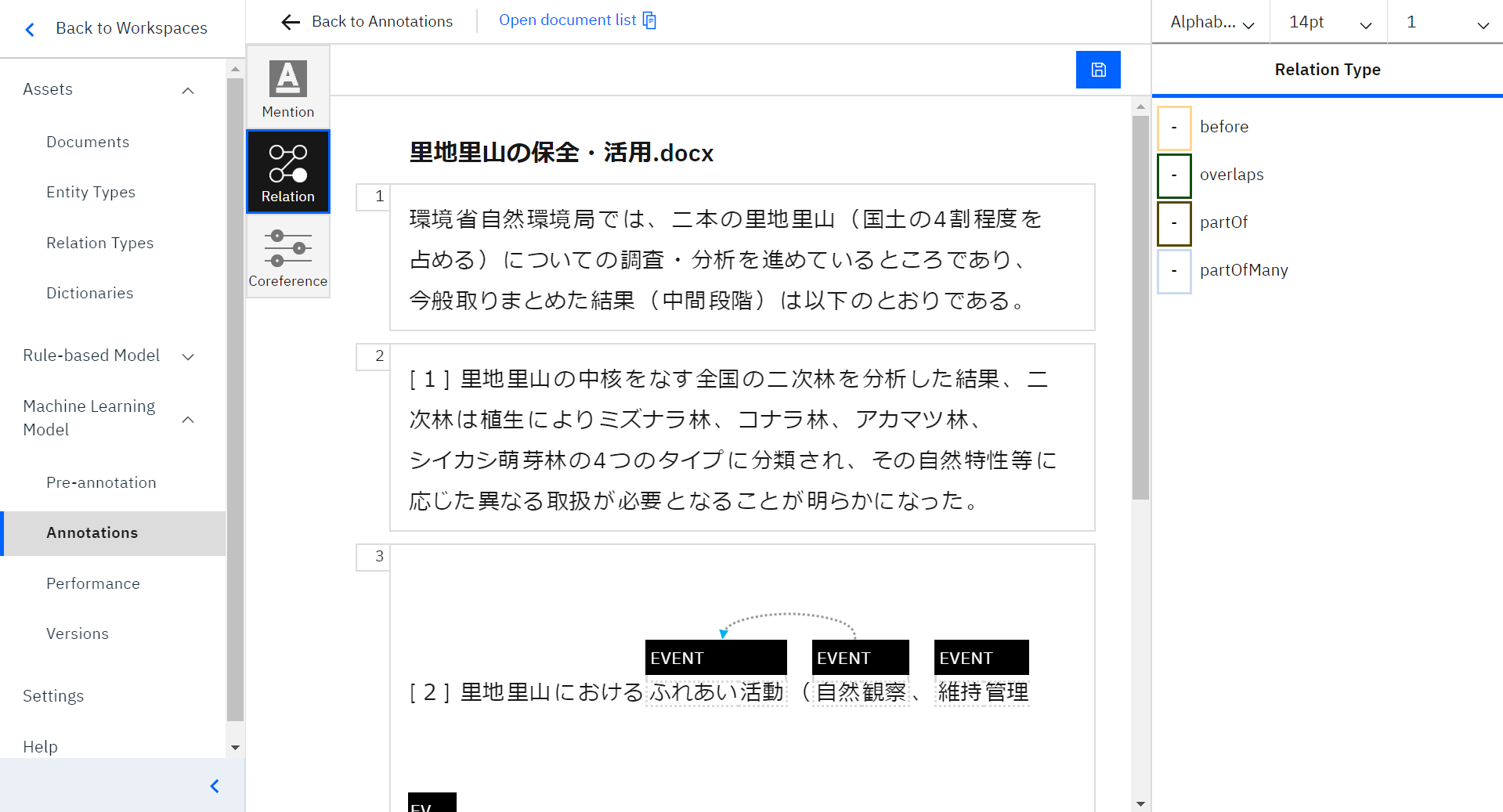
続いて、もう1つの言葉「ふれあい活動」をクリックします。すると画像のように矢印が伸びます。
右側には関係性としてふさわしいと思われるタイプが自動的に抽出されます。
今回私は、「Part of」という関係性がふさわしいと文脈から考え、選択しました。
(自然観察 is part of ふれあい活動 という関係性と判断)
選択する関係性が決まったら、右側Relation typeから「Part of」を選びダブルクリックします。
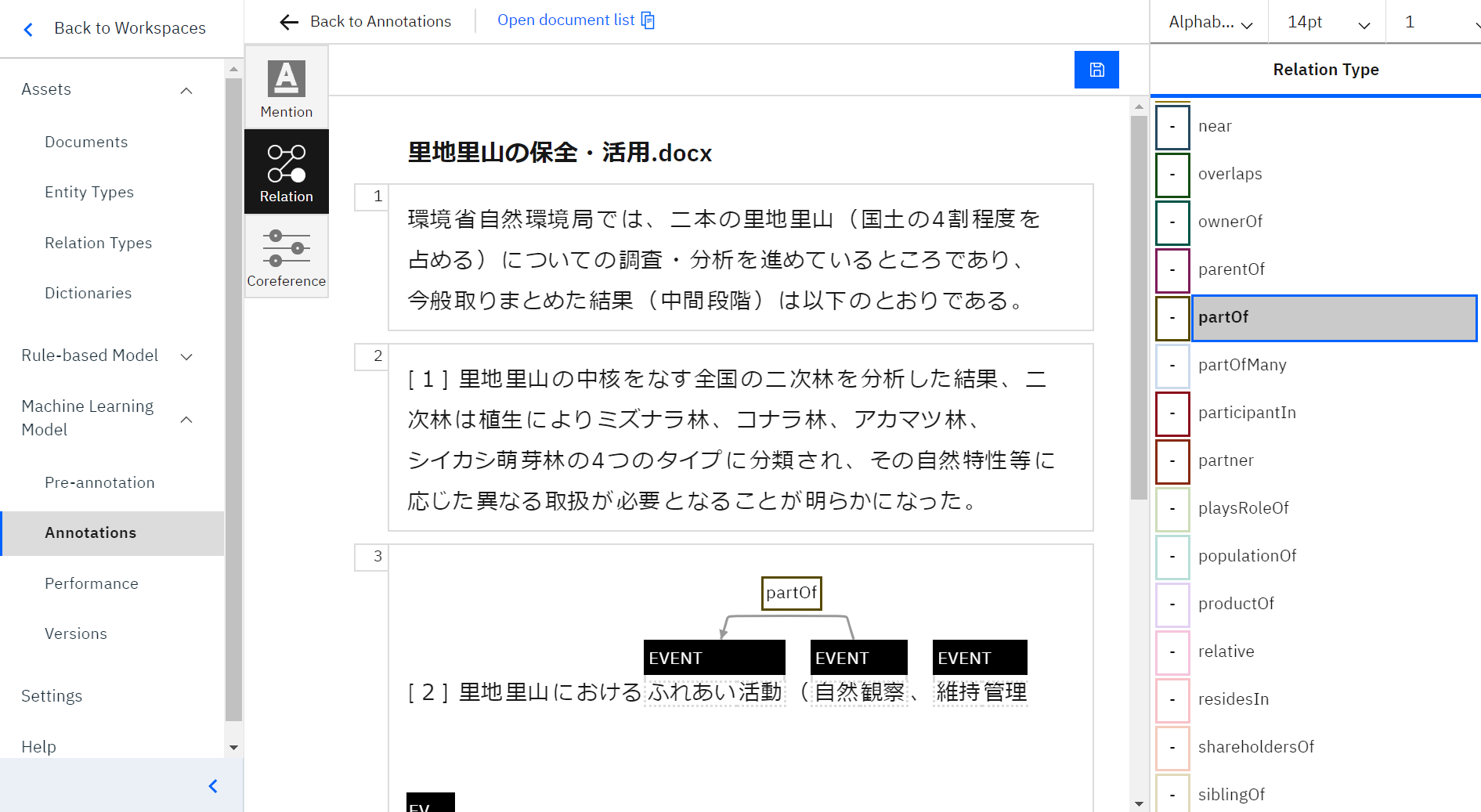
上の画像のように、くっきりした矢印と関係性が示されれば設定完了です。
Conference機能
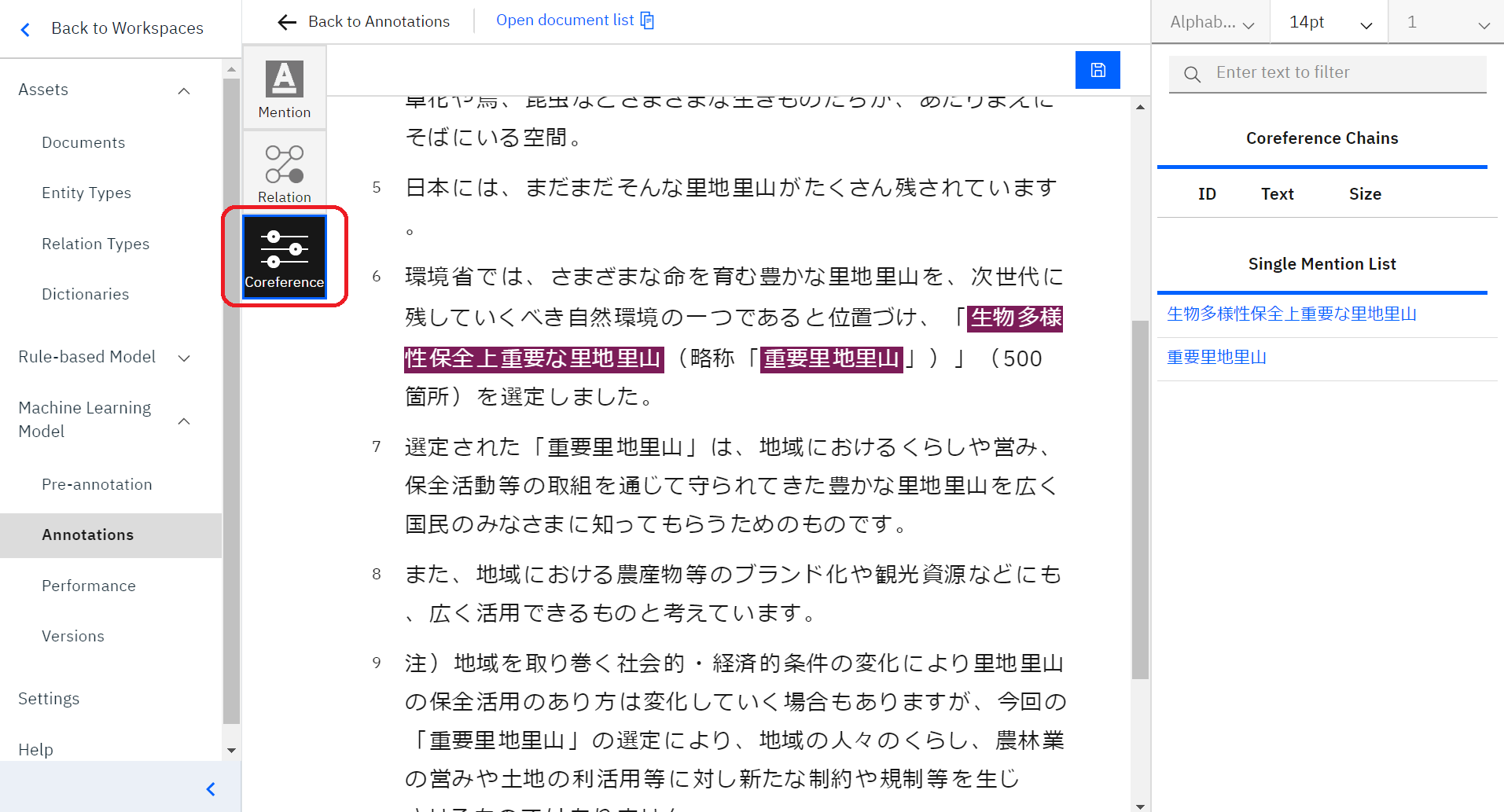
最後に③Conference機能です。この機能はエンティティーとエンティティーの同一性を設定する機能です。
赤い丸で囲っている「Conference」をクリックしてください。
今回は「生物多様性保全上重要な里地里山」と「重要里地里山」が同一性の言葉と判断し、こちらをアノテーションしていきます。
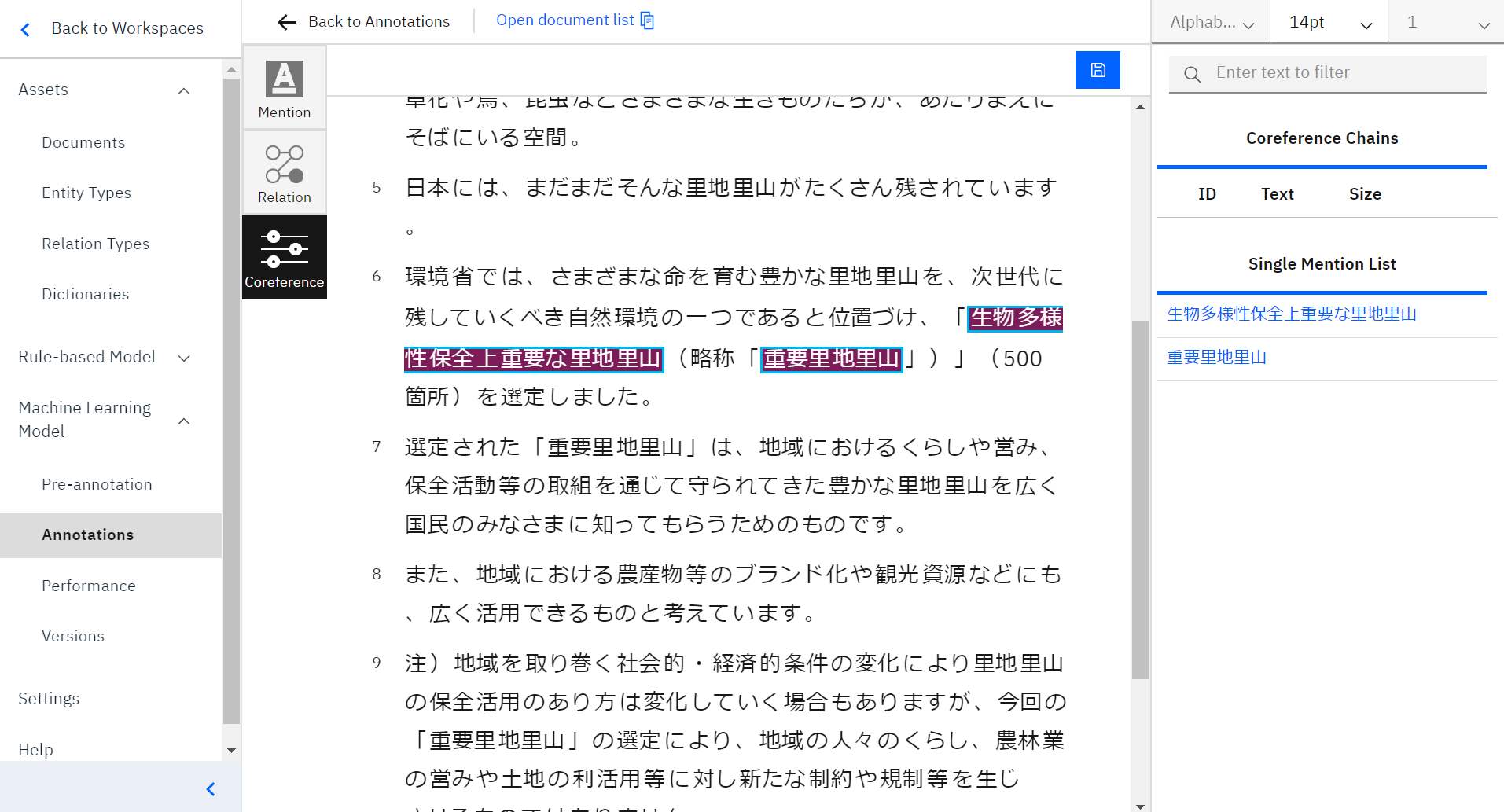
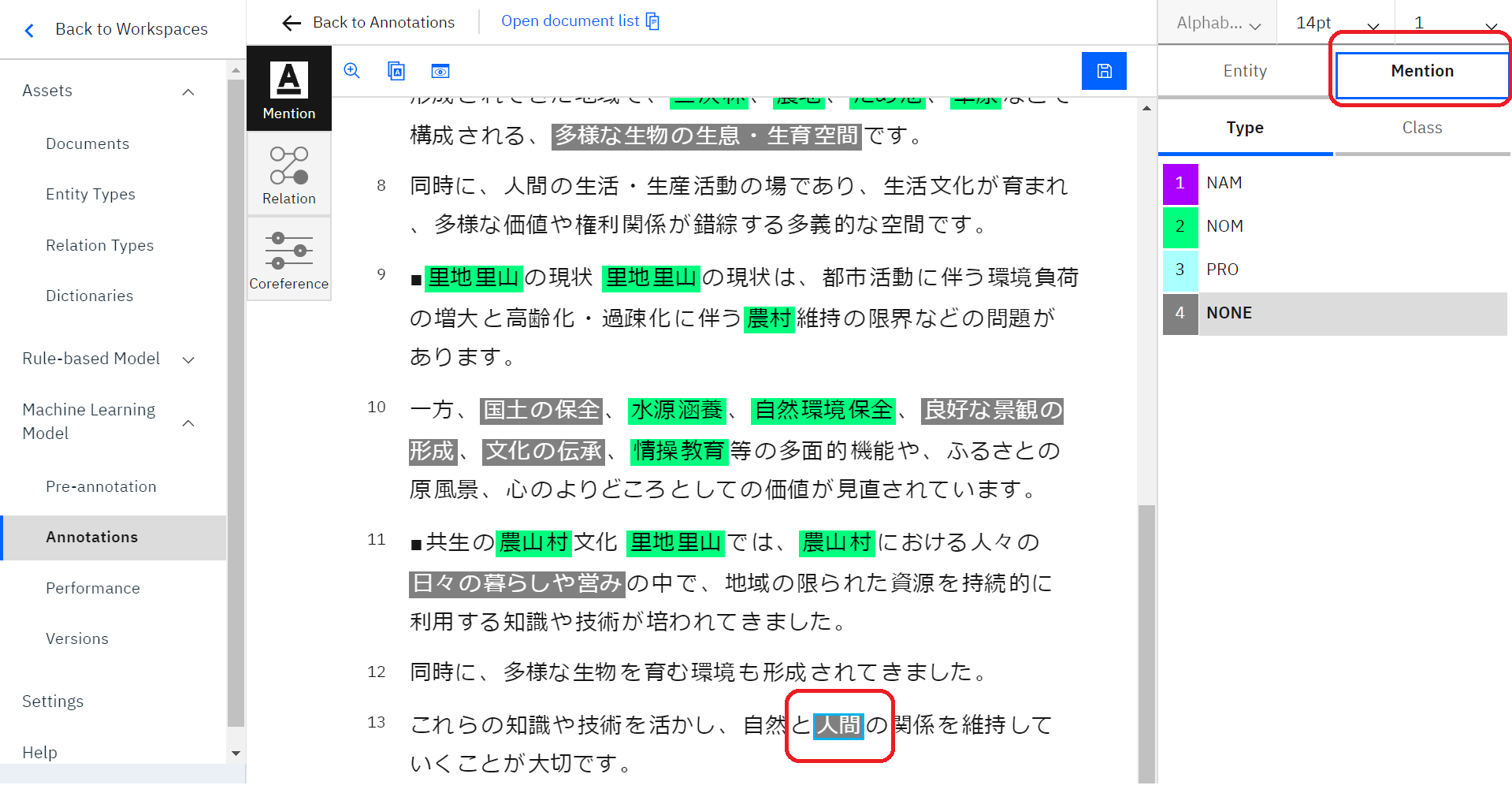
同一性を設定したい言葉をクリックして選択します。選択すると、このように言葉の周りが青くなります。
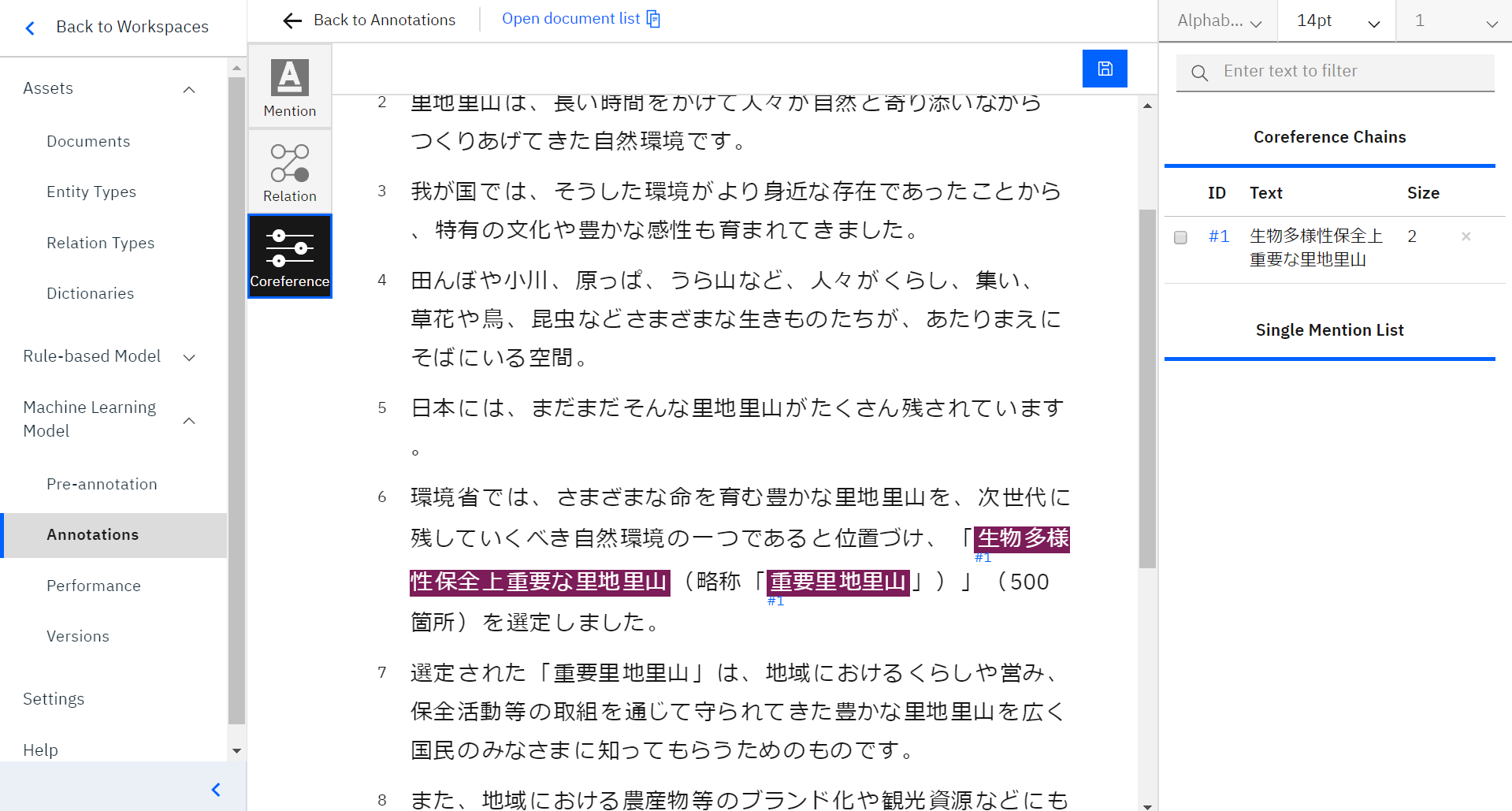
言葉を選択した状態で、もう一度言葉をクリックすると、言葉の下に小さく「#(数字)」という青い文字が付きます。右側のConference Chainsに設定したものが表示されます。
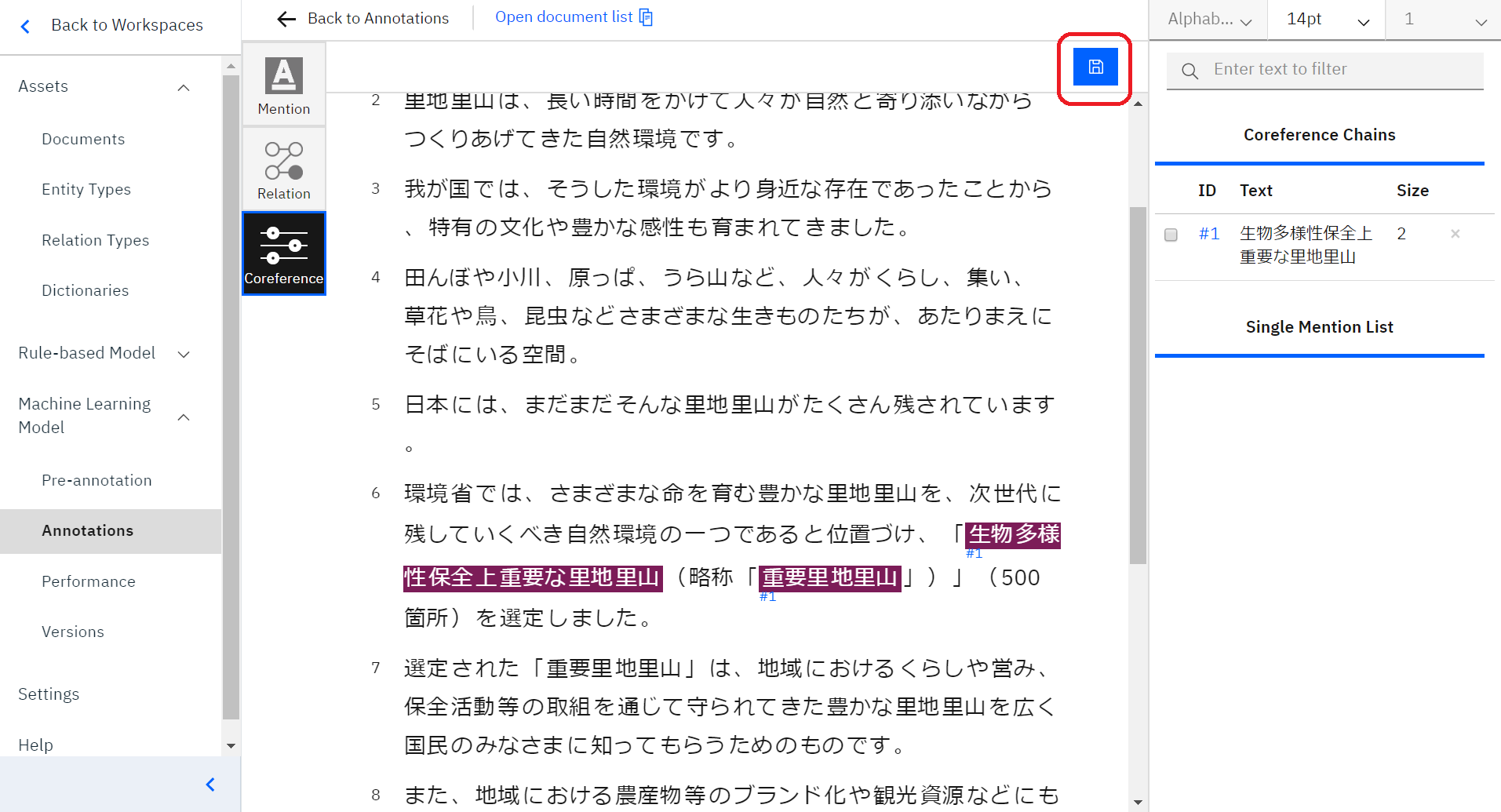
アノテーションが終了したら、右上の赤い丸で囲ってある保存マークをクリックすると、今回アノテーションした内容が保存されます。

アノテーションが終了した際、アノテーション画面で上にある「Back to Annotations」をクリックします。
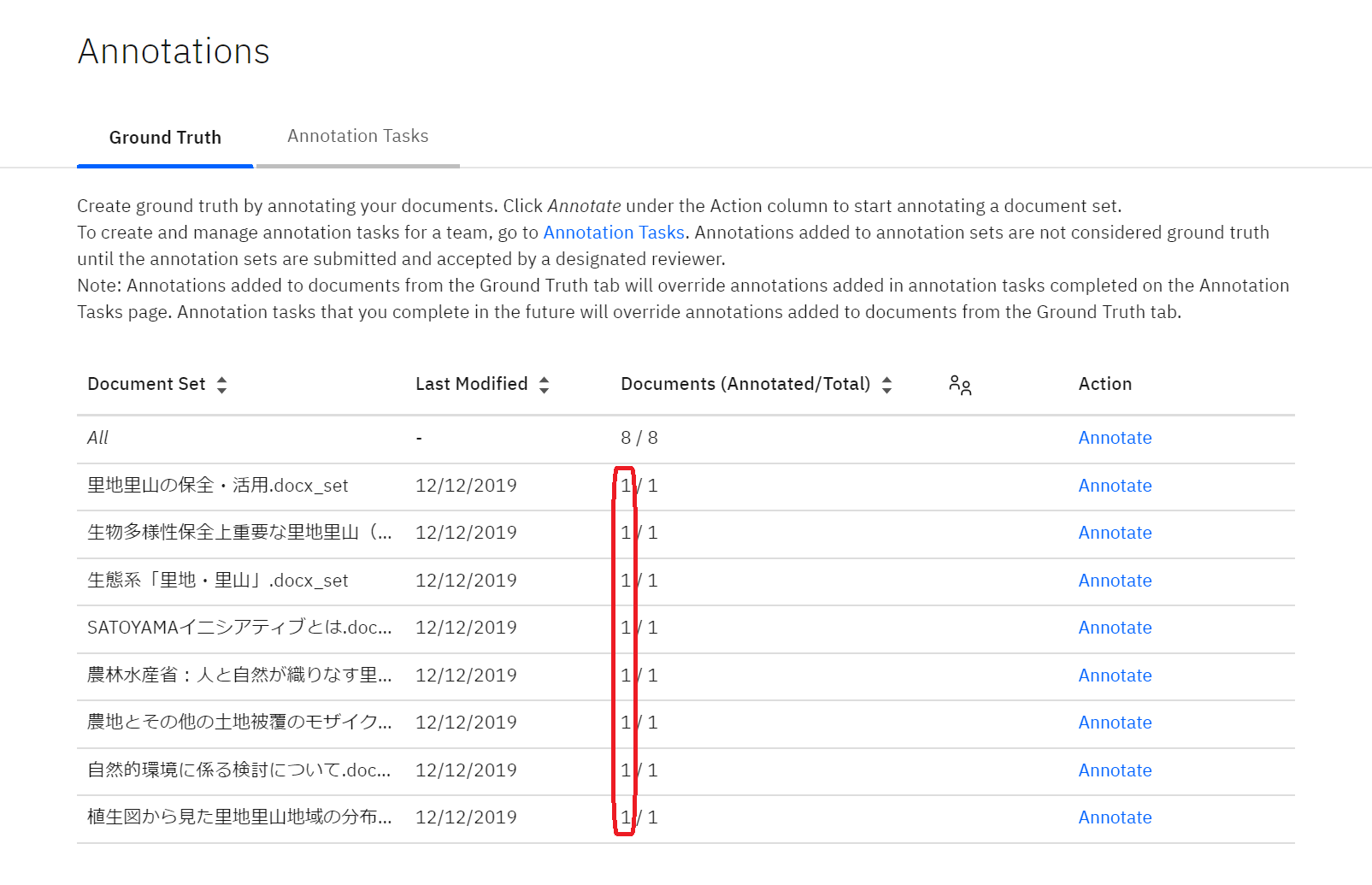
すると、上の画像のようなアノテーションするドキュメントセットの一覧が出てきます。
Documents列に「◯◯/◯◯(◯は数字)」というようにドキュメントセット毎に数字が記載されているかと思います。
左の数字がアノテーションをしたドキュメント数、右の数字がアノテーションされる予定のドキュメント数です。
左と右の数字が同じであれば、アノテーションは終了です!
モデルのトレーニング
アノテーションが完了したら、次は機械学習モデルのトレーニングを行います。
※モデルのトレーニングは10以上のドキュメントセットがないとできませんので、注意してください。
モデルのトレーニングを行うときには、左の「Performance」をクリックします。
クリックすると上のような画面が出てきます。
続いて「Train and evaluate」をクリックします。
すると、上のような画面に切り替わるかと思います。
こちらでは、どのドキュメントセットをトレーニングするか決定することができます。
すべてのドキュメントセットをトレーニングする場合は、「Document Set」列の一番上「All」にチェックをつけていただくと便利です。
「Train」をクリックすると、モデルのトレーニングが行われます。
このような画面が出てくるかと思います。
右上に「Train processing…」と出ているときはトレーニング中です。
右上に上の画像のように緑のチェックマークが表示されれば、トレーニング終了です。
左側のメニューから「Version」を選択します。
Discoveryと連携~WKSでの作業~
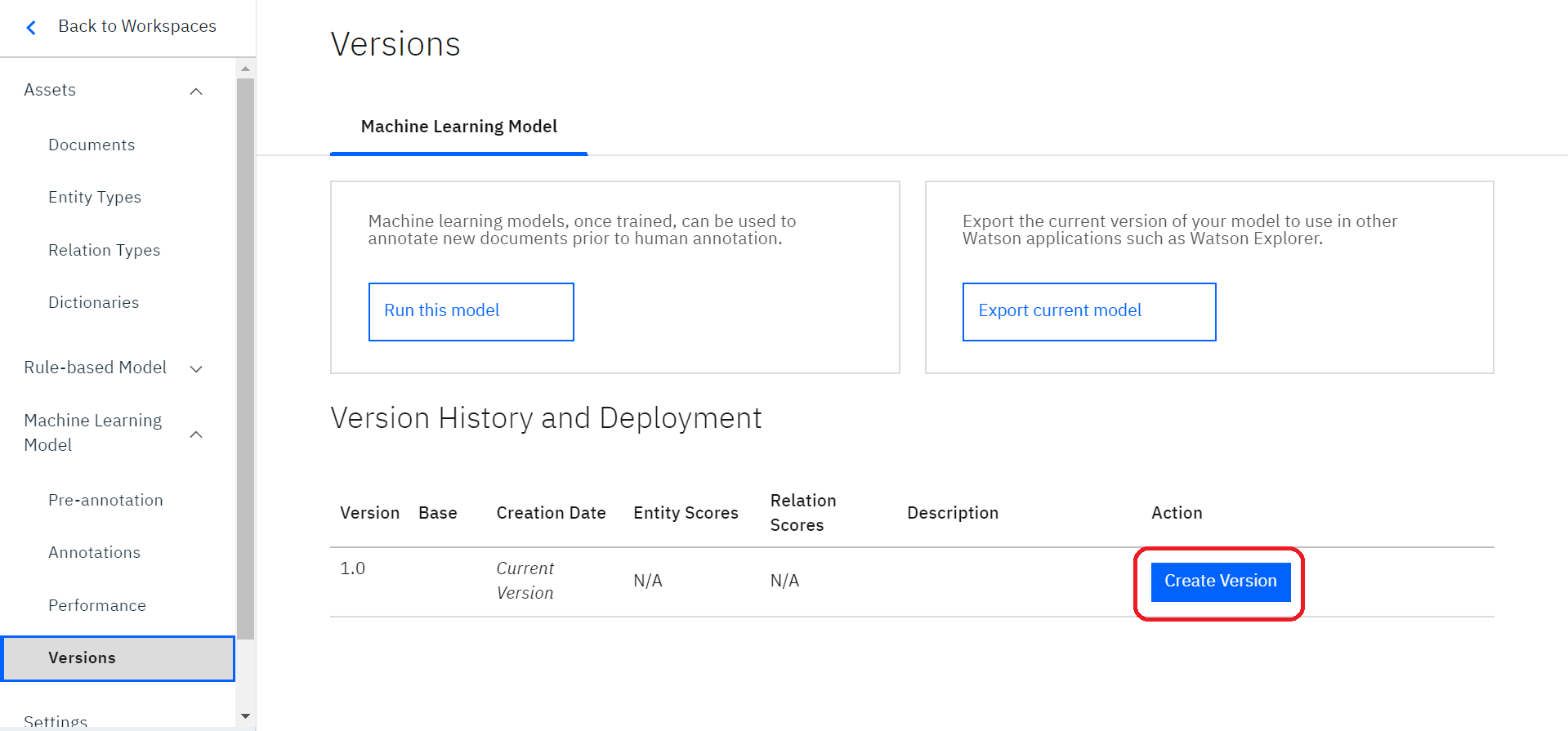
続いて、Discoveryとの連携作業を進めていきます。
先ほど作成した機械学習モデルが「Version History and Deployment」の下に表示されているかと思います。
※今回は記事作成のためにモデルを作成したため、アノテーションされたデータが少なく「Entity Scores」「Relation Scores」がそれぞれN/Aとなっていますが、うまくいけばこちらも数値が表示されます。
こちらのデータをDiscoveryと連携してよければ「Create Version」をクリックします。
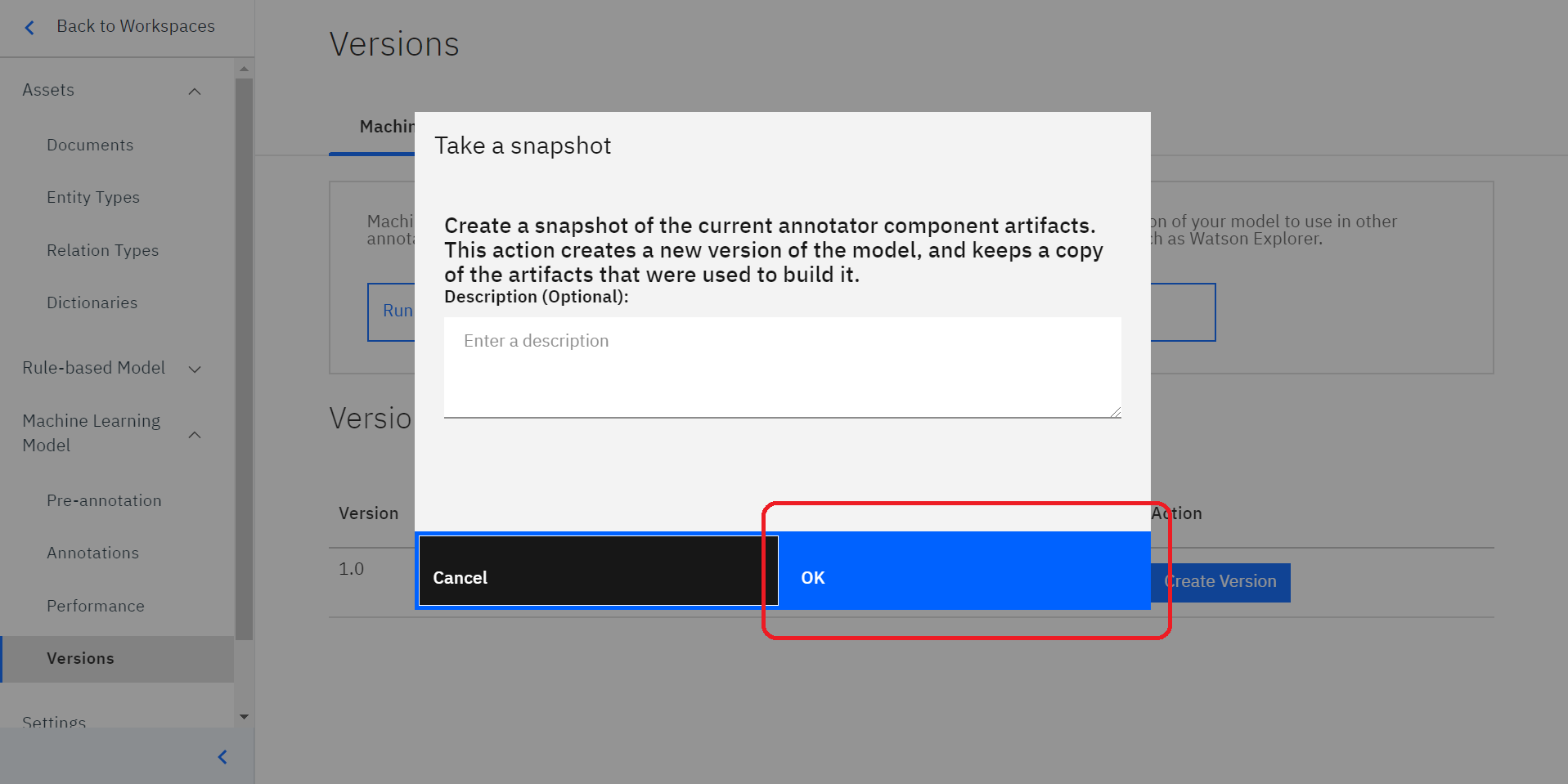
このような画面がでてきますので、「OK」をクリックしてください。
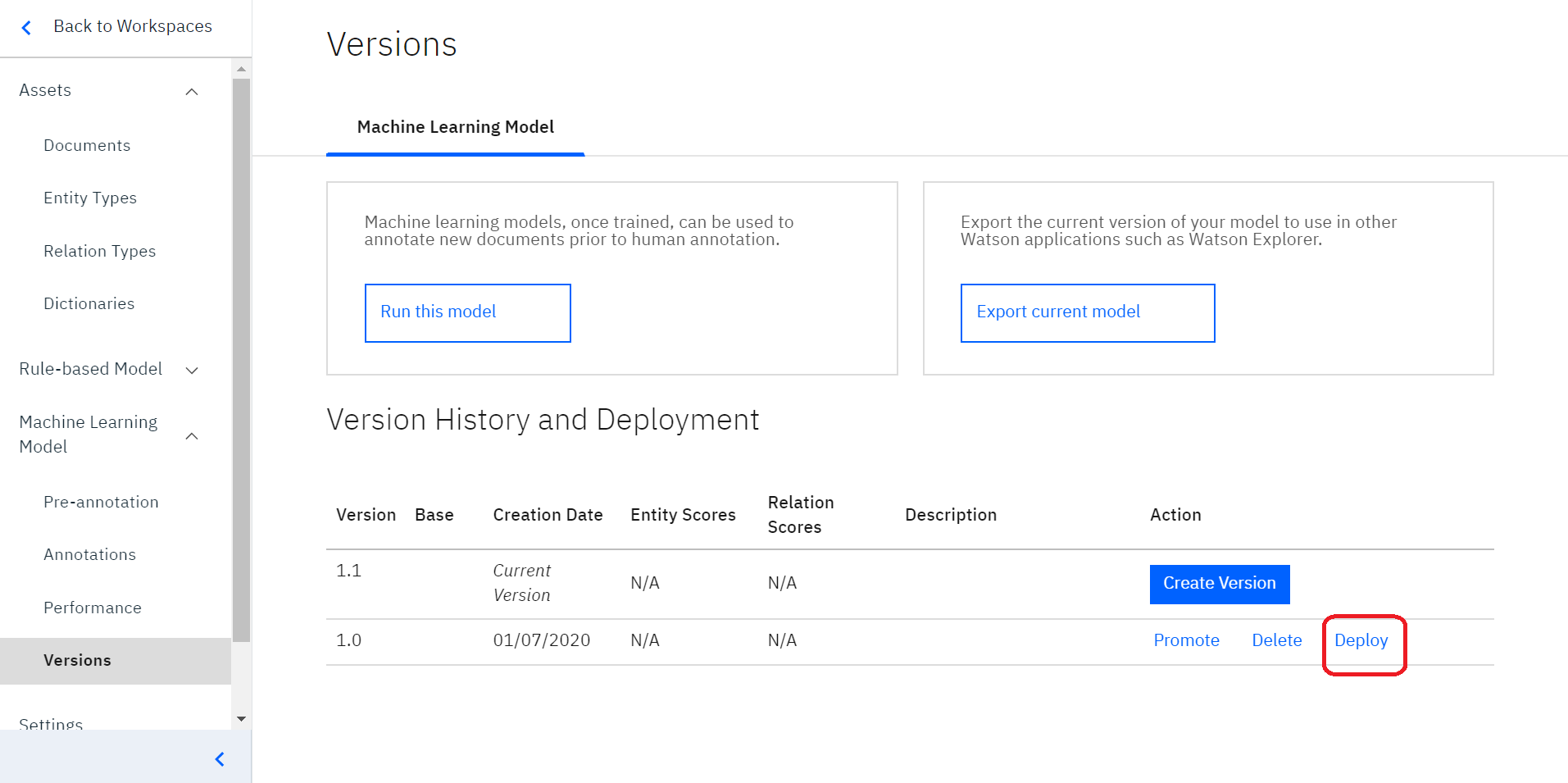
この状態になれば、Discoveryに適用することができます。「Deploy」を選択し、Discoveryで使えるようにします。
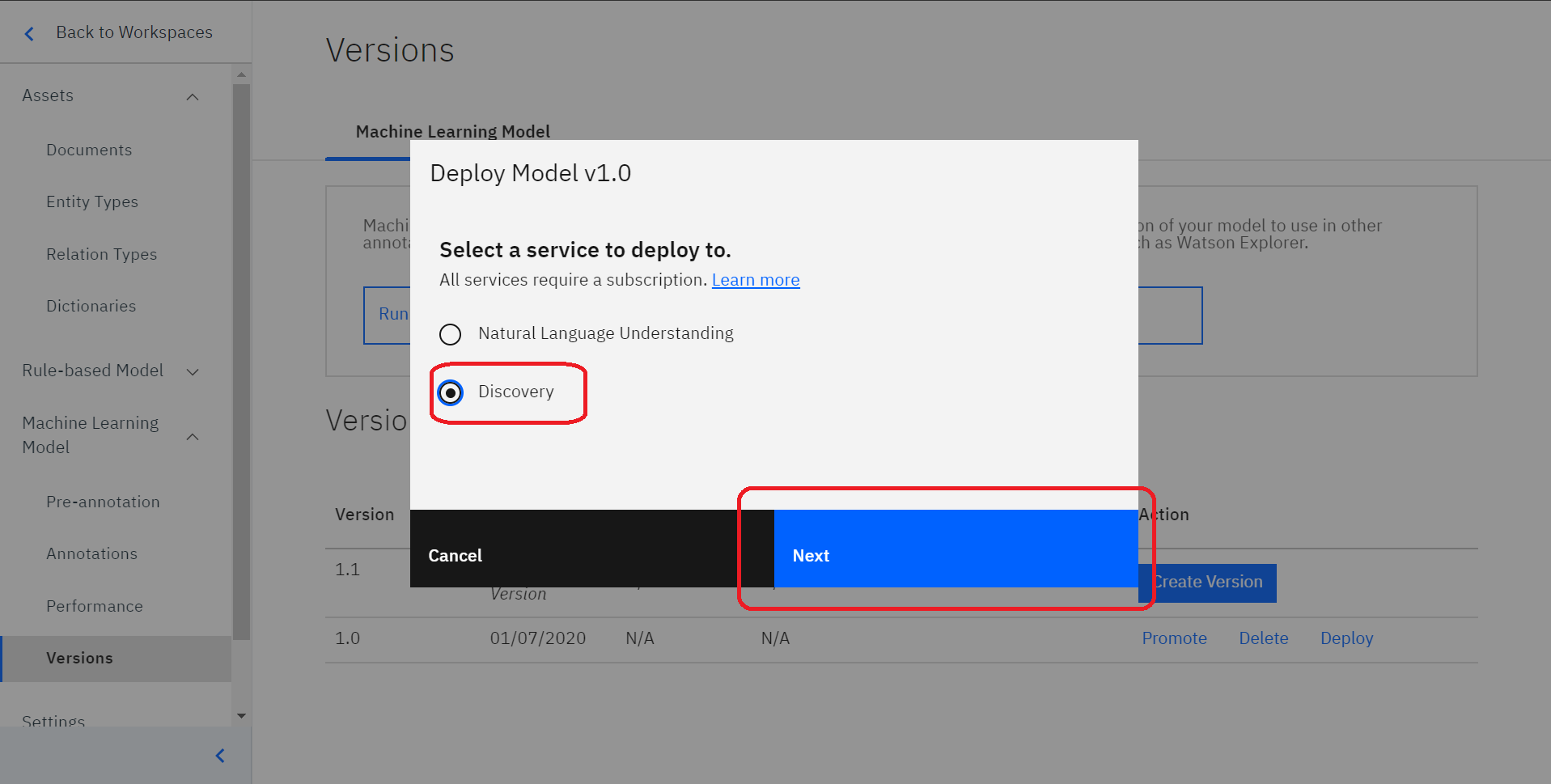
このような画面がでてきますので、「Discovery」を選択してください。そして「Next」をクリックします。
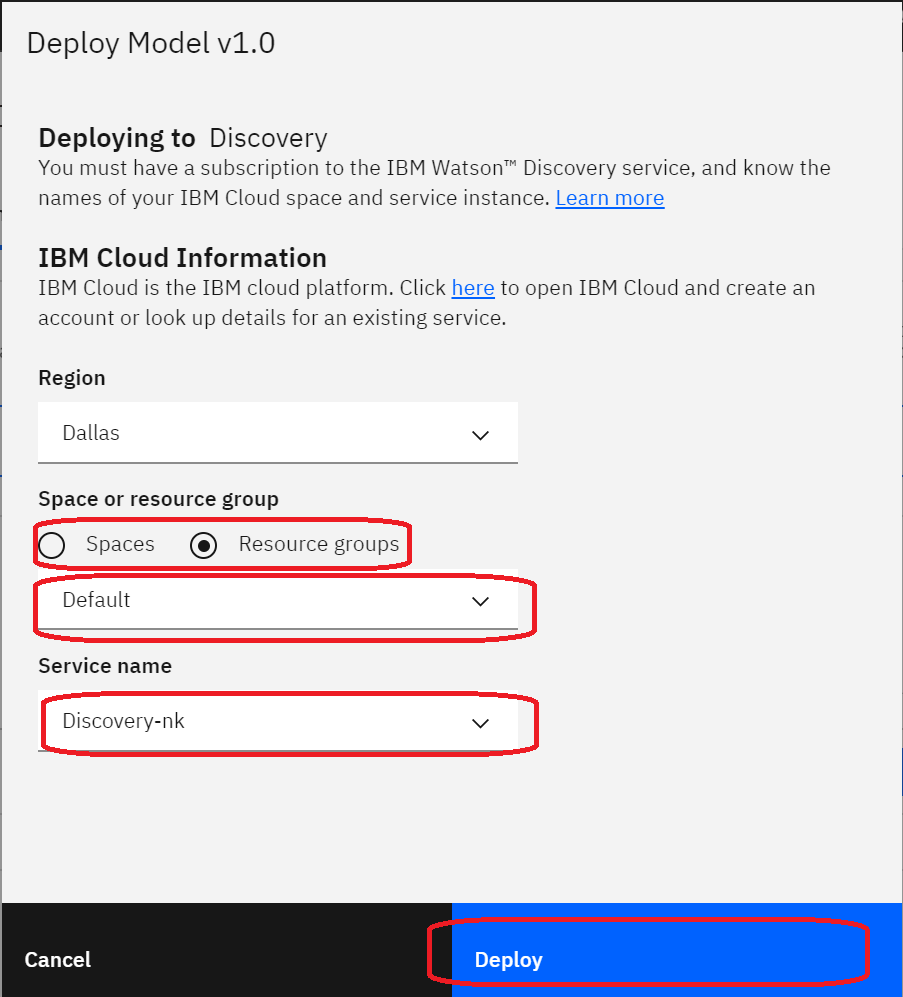
続いてこのような画面が出ますので、どのDiscoveryサービスと連携するのかを選択していきます。
赤く囲ってある部分が主に選択する部分となるので、選択してください。
選択が終了したら、Deployをクリックします。
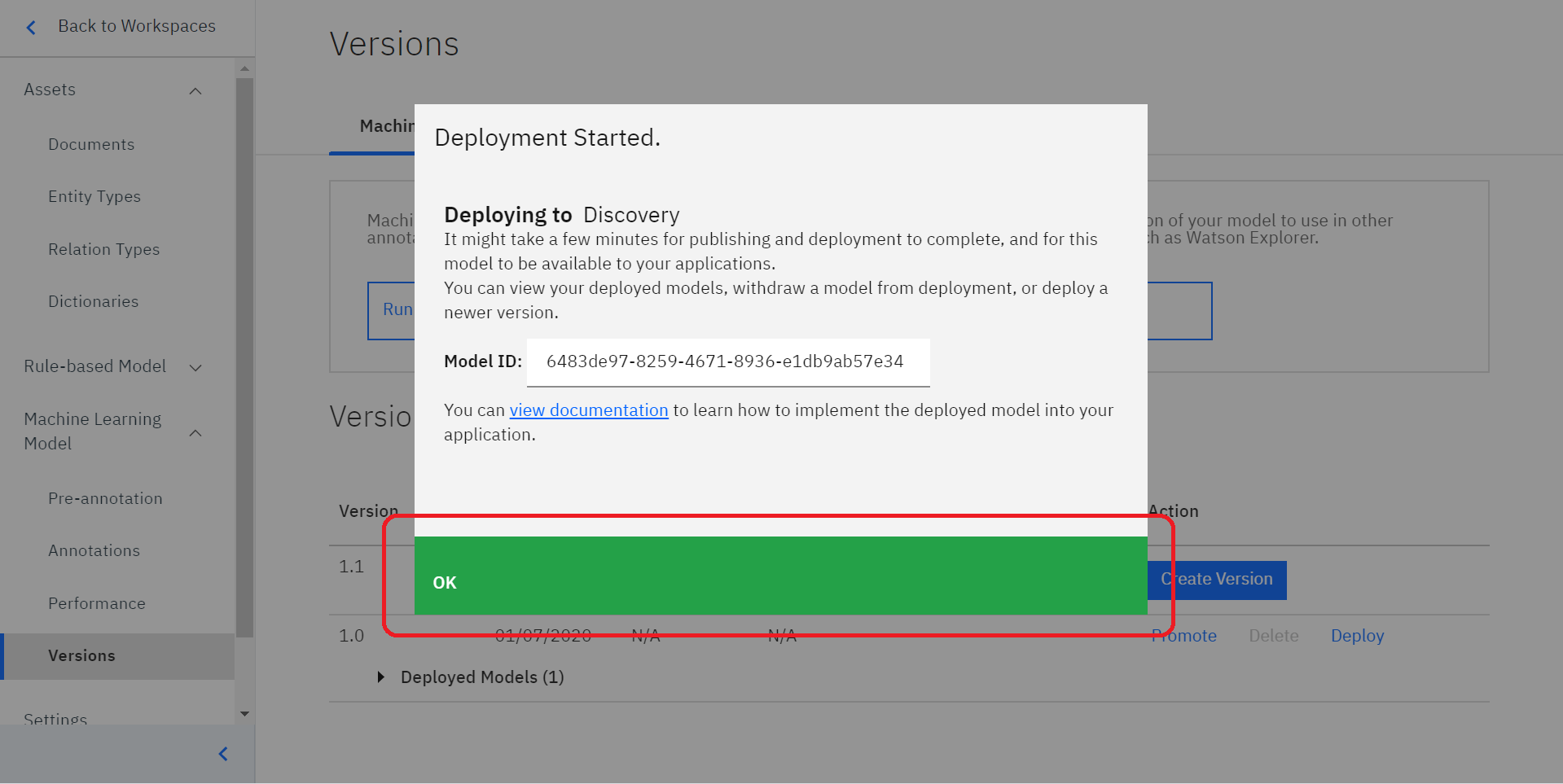
このような画面がでてきましたでしょうか?
こちらに表示されている「Model ID」をDiscoveryにコピーしOKをクリックします。
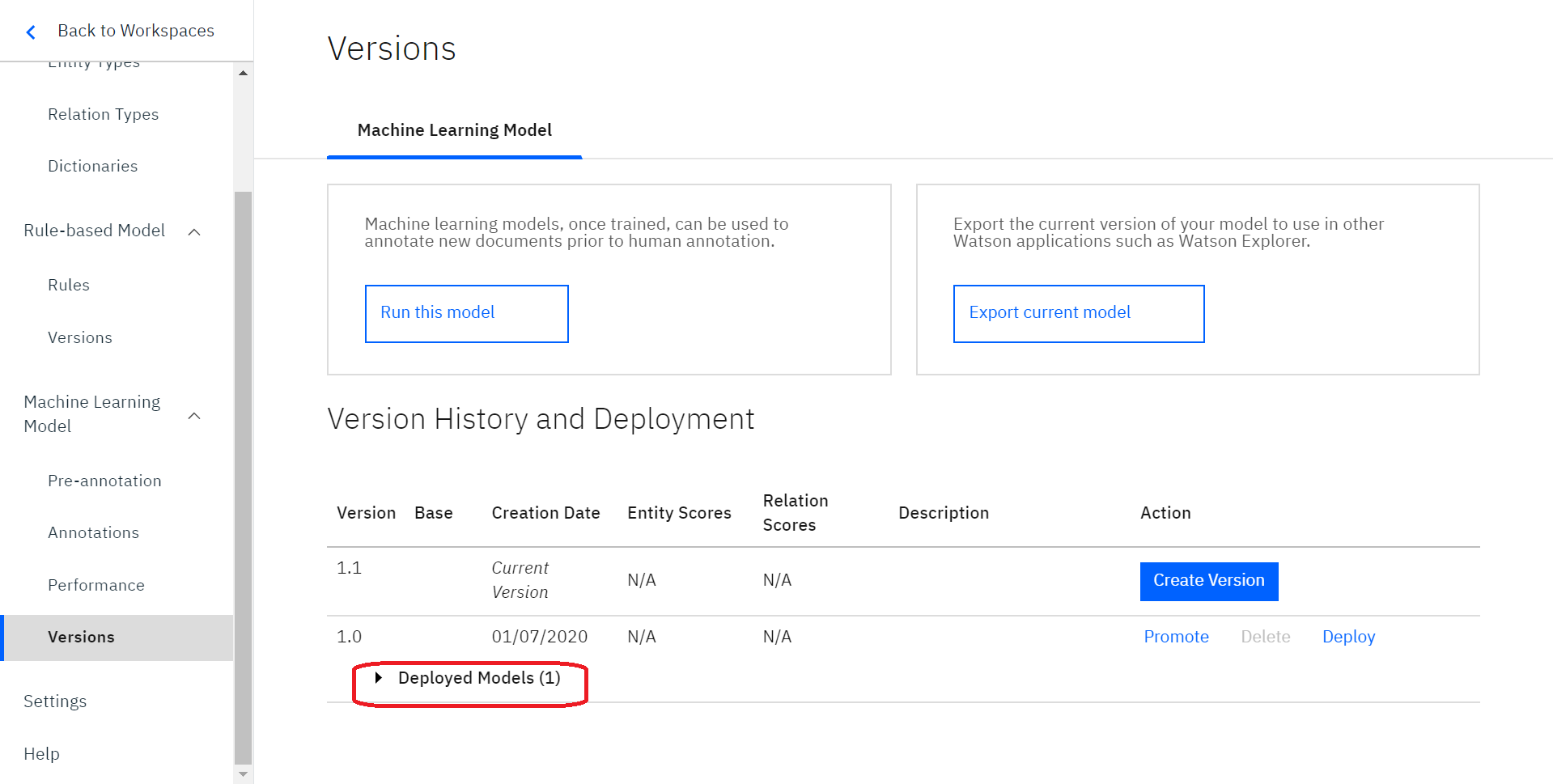
OKを押した後でも、「Model ID」は閲覧が可能です。
「Version History and Deployment」から該当の「Version Base」を見つけ、その下にある「Deployed Models」をクリックしてください。
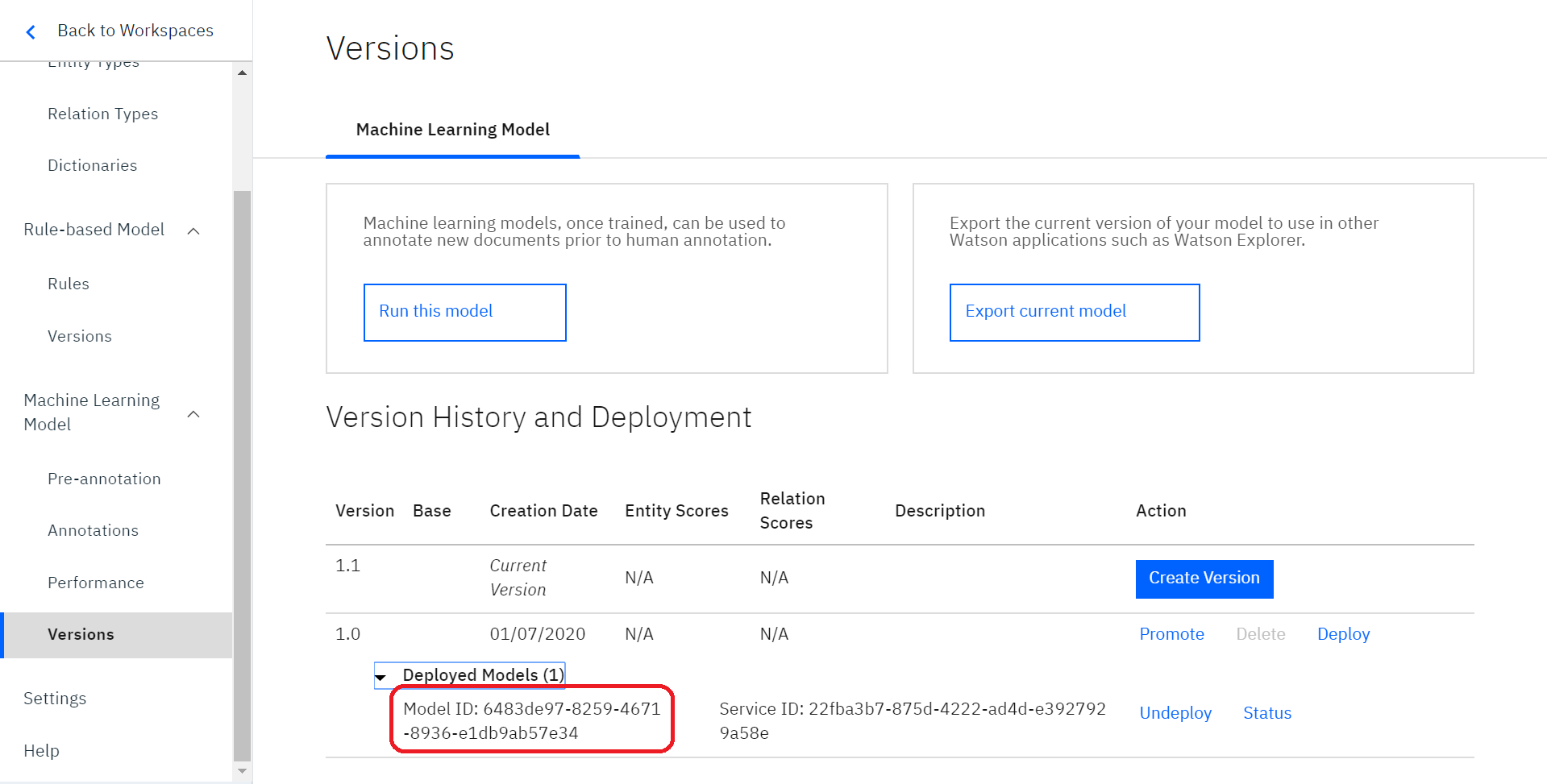
そうするとこのように先ほどと同じIDを確認することができます。
Discoveryと連携~Discoveryでの作業~
Discoveryについての詳細を知りたい方はこちらのページをご覧ください。
Discoveryを開き、Manage dataの中から連携したいデータを選びます。
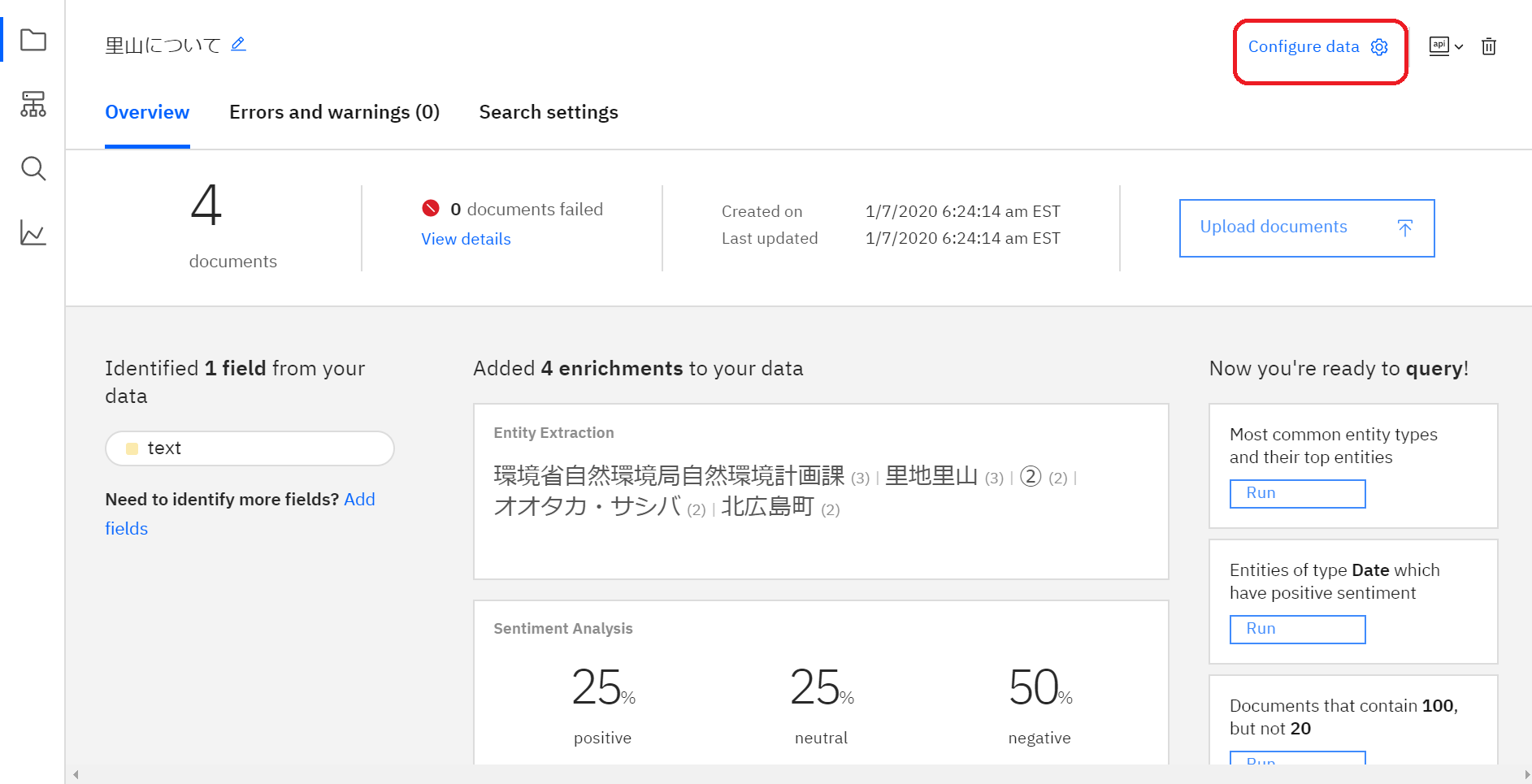
データを開いたら、画面右上の「Configure data」をクリックします。
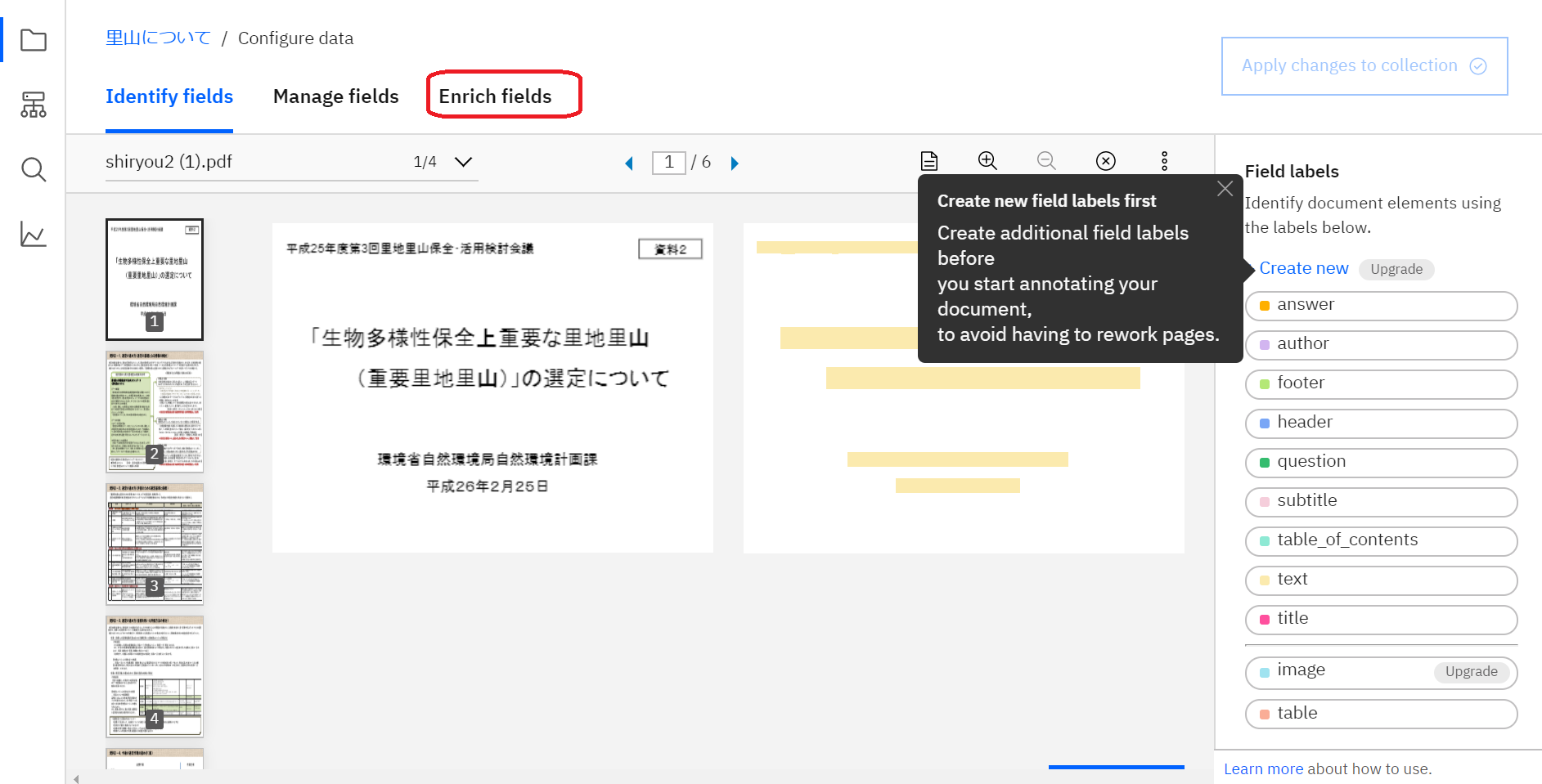
フィールド設定の画面が開きますので、「Enrich fields」をクリックします。
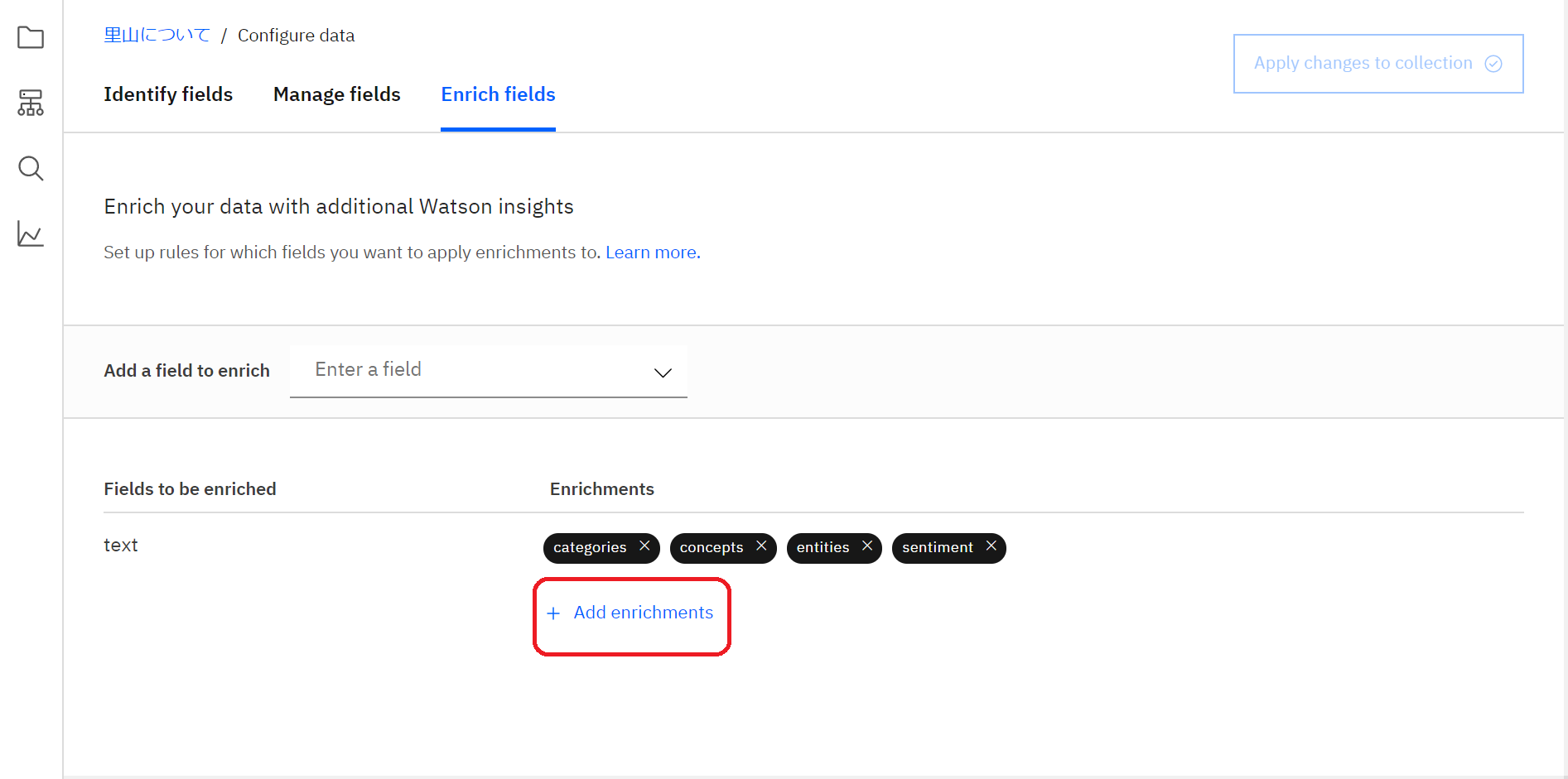
「+Add enrichments」をクリックします。
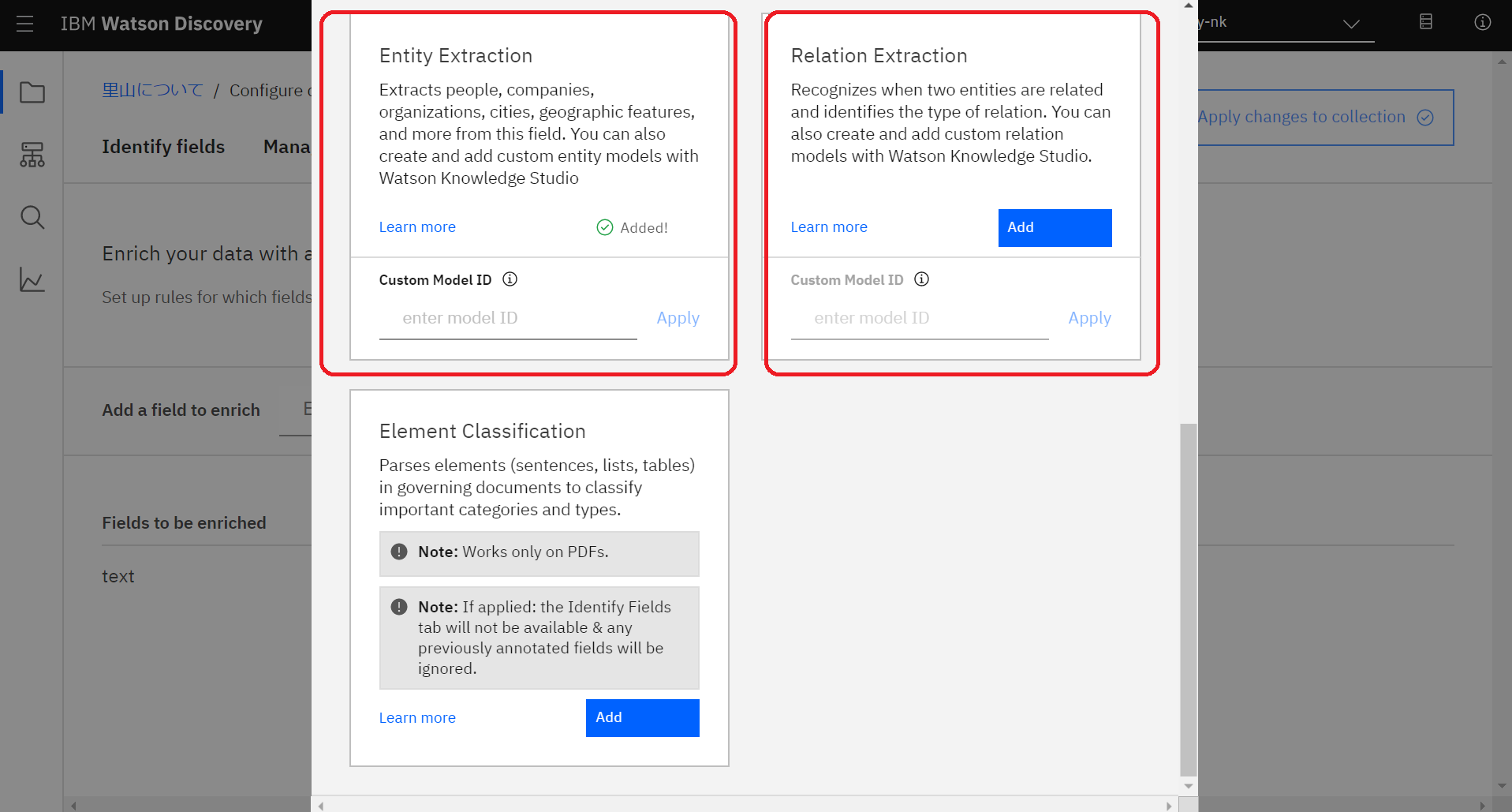
すると、「Add Enrichments」の画面が出ますので、下にスクロールしてください。
こちらの赤枠で囲ってある「Entity Extraction(エンティティー抽出)」と「Relation Extraction(関係の抽出)」がKnowledge Studioとの連携が可能なエンリッチです。
「Custom Model ID」に先ほどの「Model ID」をコピーし、貼り付け、「Apply」をクリックして連携完了です。
※エンリッチ機能にご自身で追加をしていないと、「Model ID」は入力できないので、追加をしてください。
[PR] Discovery対応の検索サービスなら「FirstSearch」
FirstSearchの特色
検索システムをWeb上で実用化するなら弊社「FirstSearch」がおすすめです。
・Discoveryの各機能に対応
・ご要望・業務内容に応じたカスタマイズに対応ができる
・姉妹製品「FirstContact」との連携可能
今なら初月の月額費が無料!
なんと初月無料で検索システムをご利用可能です!この機会にぜひお申し込みください。